
Stable diffusion is a type of deep learning AI model that generates images from textural descriptions. It belongs to a category of models called ‘diffusion models’. These models start with random noise that they repeatedly refine into an image that matches the textural description that you send to it.
One of the key features of stable diffusion is that it is optimized for consumer grade hardware. Anyone can run it on a modern computer, though it will take advantage of high performance video cards (GPUs) for accelerated processing.
Stable diffusion is open source, it is available and accessible to any developer or creator that wants to use it in their work. New contributions and custom models have been created to extend the work that was done for stable diffusion for various use cases. Civitai is a popular place to host such models and they have them organized and tagged so you can find models that are highly tuned for what you’re trying to do–such as to help make images for realistic buildings or vehicles, for example.
Testing Generative AI Models: The Use Case
This is all fine and well, but you might want to try out a couple of different models for your particular use case.
Let’s say you host a fantasy video game application. And as part of that, for every user that signs up, they get an automatically generated image created for them based on their character’s description. Creating these images is fun. Many users seem to really like this personalized part of the game experience.
Generating these images is fairly computationally and time intensive though, and you’re looking to experiment to see if you can save some compute costs without damaging your well earned reputation among the players that enjoy your game.
You want to test a few things to reduce the compute required of the image generation. First, would be to reduce the size of the image. Secondly, we’d want to reduce the complexity of the prompt we’re using–reducing some of the additional words we use to make the fantasy image prompt smaller. Finally, we may want to also test different diffusion models to see if one is more efficient than the other.
Starting Code
We can start with a basic Stable Diffusion code sample. In this sample we are running diffusion on the CPU, but you can change the pipeline to use cuda cores on your GPU if you have them by changing the value from pipeline.to(“cpu”) to pipeline.to(“cuda”)
import torch
from diffusers import StableDiffusionPipeline
import numpy as np
import sys
userId="user1"
# this is the user's description of themselves
prompt="A superstar engineer"
def generate_images(prompt, num_images, resolution, model_name="CompVis/stable-diffusion-v1-4"):
"""
Generate images using the Stable Diffusion model.
Parameters:
- prompt (str): The description of the image to generate.
- num_images (int): The number of images to generate.
- resolution (str): The resolution of the generated images, formatted as 'widthxheight'.
Returns:
- images (List[PIL.Image]): A list of generated images.
"""
# Parse resolution
width, height = map(int, resolution.split("x"))
# Initialize the model
pipeline = StableDiffusionPipeline.from_pretrained(model_name)
pipeline = pipeline.to("cpu")
# Generate images
images = pipeline([prompt] * num_images, width=width, height=height).images
return images
#image resolution
resolution="512x512"
# extra text to add to the prompt
extraText = " in a futuristic fantasy world. Colorful, exciting, engaging. Highly detailed"
# Example usage
if __name__ == "__main__":
images = generate_images(prompt=prompt+extraText, num_images=1, resolution=resolution)
for i, img in enumerate(images, start=1):
img.save(f"image_{i}.png")
The image output from this model can be seen below. Pretty nice!

Setting Up Our Feature Flags
Now, of course we talked about the three pieces of our code that we want to make parameterizable.
- Image size
- Prompt complexity
- Stable Diffusion model.
Let’s go into Split and make flags for each of these.
Creating the Flags in Split
For the image size, we will make a flag called backEnd_imageGenerator_makeSmallerImage and we will tag it properly to ensure that other teams working on AI and Stable Diffusion based features are aware of it.
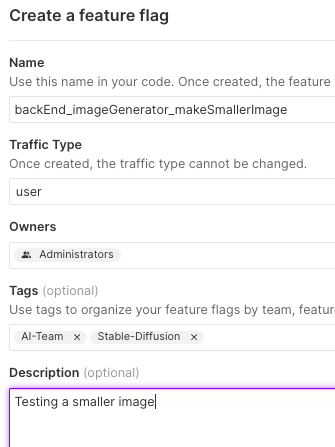
We will do this for our prompt complexity flag as well, we will call it backEnd_imageGenerator_makeSimplerPrompt
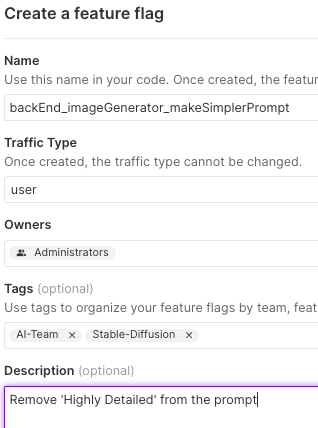
And finally, for the model itself, we will explore using an updated model from a group called RunwayML. This would be Stable Diffusion 1.5. We will create this flag and call it backEnd_imageGenerator_useStableDiffusion15.
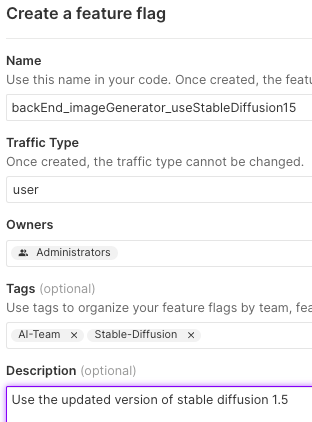
Now that we have our flags created in Split, we will need to update our code to use them.
Using the flags in Code
The first thing we will need to do is import and instantiate the Split Python SDK.
We will do this after the other imports and before the generate_images function is defined.
You will also need to replace the YOUR_SDK_KEY with a server side Split SDK key. If you are an administrator this can be retrieved from the Syntax option at the top right of the flag definition:

from splitio import get_factory
from splitio.exceptions import TimeoutException
factory = get_factory('YOUR_SDK_KEY', config={'impressionsMode': 'OPTIMIZED'})
try:
factory.block_until_ready(5)
except TimeoutException:
# The SDK failed to initialize in 5 seconds. Abort!
sys.exit()
split = factory.client()Now that we’ve imported Split and instantiated the Split SDK, we can use it to parameterize our code using feature flags.
The first place we want to look at is the image resolution. We want to look at any effects from reducing it from 512×512 to 384×512.
So let’s look at what it takes to do that:
makeSmallerImage = split.get_treatment(userId, 'backEnd_imageGenerator_makeSmallerImage')
if(makeSmallerImage == 'on'):
#image resolution
resolution="384x512"
else:
# notice here we're not explicitly testing for 'off' - this is important in case the SDK returns control
resolution="512x512"Now let’s do this for the prompt as well.
makeSimplerPrompt = split.get_treatment(userId, 'backEnd_imageGenerator_makeSimplerPrompt')
if(makeSimplerPrompt == 'on'):
# extra text to add to the prompt
extraText = " in a futuristic fantasy world. Colorful, exciting, engaging."
else:
extraText = " in a futuristic fantasy world. Colorful, exciting, engaging. Highly detailed"Notice we removed the ‘highly detailed’ from the prompt in order to test if that might be something people might not notice but could make the image generation simpler.
Finally, we can look at adding parameterization for the actual model itself.
useStableDiffusion15 = split.get_treatment(userId, 'backEnd_imageGenerator_useStableDiffusion15')
if(useStableDiffusion15 =='on'):
modelName= "runwayml/stable-diffusion-v1-5"
else:
modelName= "CompVis/stable-diffusion-v1-4"
# Example usage
if __name__ == "__main__":
images = generate_images(prompt=prompt+extraText, num_images=1, resolution=resolution, model_name=modelName)
for i, img in enumerate(images, start=1):
img.save(f"image_{i}.png")Now that we’ve added code to control these parameters via code, we can go into Split’s console and enable or disable them as needed.
Final Code
Here is what the code with all 3 flags in it looks like:
import torch
from diffusers import StableDiffusionPipeline
import numpy as np
import sys
from splitio import get_factory
from splitio.exceptions import TimeoutException
factory = get_factory('1t4ff5a6o3ocnmmmnqgaebpfm7kta7kqhgli', config={'impressionsMode': 'OPTIMIZED'})
try:
factory.block_until_ready(5)
except TimeoutException:
# The SDK failed to initialize in 5 seconds. Abort!
sys.exit()
split = factory.client()
userId="user1"
# this is the user's description of themselves
prompt="A superstar engineer"
def generate_images(prompt, num_images, resolution, model_name="CompVis/stable-diffusion-v1-4"):
"""
Generate images using the Stable Diffusion model.
Parameters:
- prompt (str): The description of the image to generate.
- num_images (int): The number of images to generate.
- resolution (str): The resolution of the generated images, formatted as 'widthxheight'.
Returns:
- images (List[PIL.Image]): A list of generated images.
"""
# Parse resolution
width, height = map(int, resolution.split("x"))
# Initialize the model
pipeline = StableDiffusionPipeline.from_pretrained(model_name)
pipeline = pipeline.to("cpu")
# Generate images
images = pipeline([prompt] * num_images, width=width, height=height).images
return images
makeSmallerImage = split.get_treatment(userId, 'backEnd_imageGenerator_makeSmallerImage')
if(makeSmallerImage == 'on'):
#image resolution
resolution="384x512"
else:
# notice here we're not explicitly testing for 'off' - this is important in case the SDK returns control
resolution="512x512"
makeSimplerPrompt = split.get_treatment(userId, 'backEnd_imageGenerator_makeSimplerPrompt')
if(makeSimplerPrompt == 'on'):
# extra text to add to the prompt
extraText = " in a futuristic fantasy world. Colorful, exciting, engaging."
else:
extraText = " in a futuristic fantasy world. Colorful, exciting, engaging. Highly detailed"
useStableDiffusion15 = split.get_treatment(userId, 'backEnd_imageGenerator_useStableDiffusion15')
if(useStableDiffusion15 =='on'):
modelName= "runwayml/stable-diffusion-v1-5"
else:
modelName= "CompVis/stable-diffusion-v1-4"
# Example usage
if __name__ == "__main__":
images = generate_images(prompt=prompt+extraText, num_images=1, resolution=resolution, model_name=modelName)
for i, img in enumerate(images, start=1):
img.save(f"image_{i}.png")And here’s what an image generated with these new parameters looks like:

Future Experiments
We can now also proceed to do a percentage based rollout to look at metrics we might be interested in, such as image generation time or CPU usage during the image generation process.
We might also review metrics such as engagement or in-game purchases to see if the updated images have any effect on those, positively or negatively.
With Split’s IFID functionality you will know which feature is impacting your metrics.
We can also experiment with using Split’s Dynamic Configuration to hold parameters used within the feature flagging system itself.
Overall, feature flags allow us to have fine grained control over the image generation process for Stable Diffusion like parameterized image generation tooling. We can use this for evaluation and testing of different approaches for an application, letting us use statistically proven methods to answer questions on application performance, user engagement, and much more.
Switch It On With Split
The Split Feature Data Platform™ gives you the confidence to move fast without breaking things. Set up feature flags and safely deploy to production, controlling who sees which features and when. Connect every flag to contextual data, so you can know if your features are making things better or worse and act without hesitation. Effortlessly conduct feature experiments like A/B tests without slowing down. Whether you’re looking to increase your releases, to decrease your MTTR, or to ignite your dev team without burning them out–Split is both a feature management platform and partnership to revolutionize the way the work gets done. Schedule a demo to learn more.
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.