
At Split we believe in the power of metrics, and are always striving to improve the ways we help our users make more data-driven product decisions. In this previous post we talked about the importance of understanding the impact of a new feature release via key and guardrail metrics.
With our new alert policies, you can utilize the power of metrics even further. Alert policies let you know immediately if there are any severe degradations in your metrics at the beginning of a new feature release. This powerful new functionality allows engineers and product managers alike to take remedial action as soon as users are negatively impacted.
An alert policy can be applied to any metric that you want to check for severe degradations such as ‘page load time per user’ or ‘number of errors per user’. This is especially useful when applied to engineering guardrail metrics as these are likely to be impacted soon after a new release versus a business metric that may take longer to be influenced.
You can configure a specific degradation threshold for each environment you operate in. Split gives you the flexibility to customize who should be notified if your metric degrades beyond the specified threshold for each environment, as well as the ability to attach any run books or action guidelines for when an alert on a metric is fired.
Once you have deployed a new feature behind a split, your metrics with alert policies will be checked for degradations beyond your specified threshold. If no alerts fire, then you will see the following screen and have peace of mind:
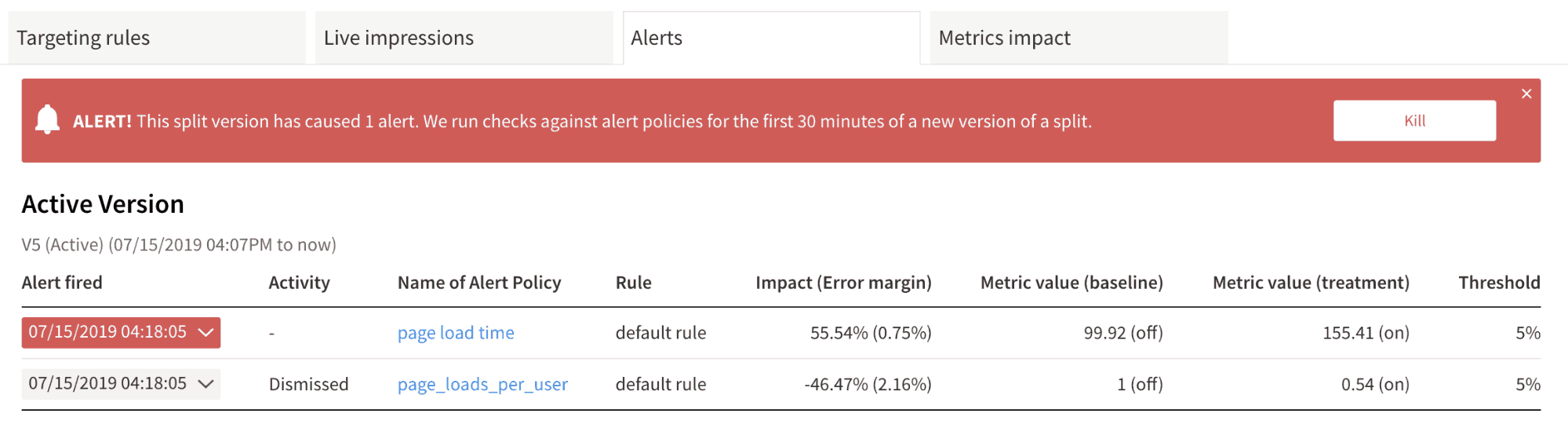
If a metric has degraded beyond the alerting threshold, we provide you with the relevant information so you can understand what caused the alert. You also have the option to dismiss the alert or kill the split immediately.
Confident alerts
Split alerts check for differences that are significantly larger than your set threshold, and in the opposite direction to your metric, using a 1-sided t-test. We run the calculations with an increased frequency as more data arrives at the start of a new version of a split and we use a stricter criteria for significance for alerting in order to minimize the false positive rate.
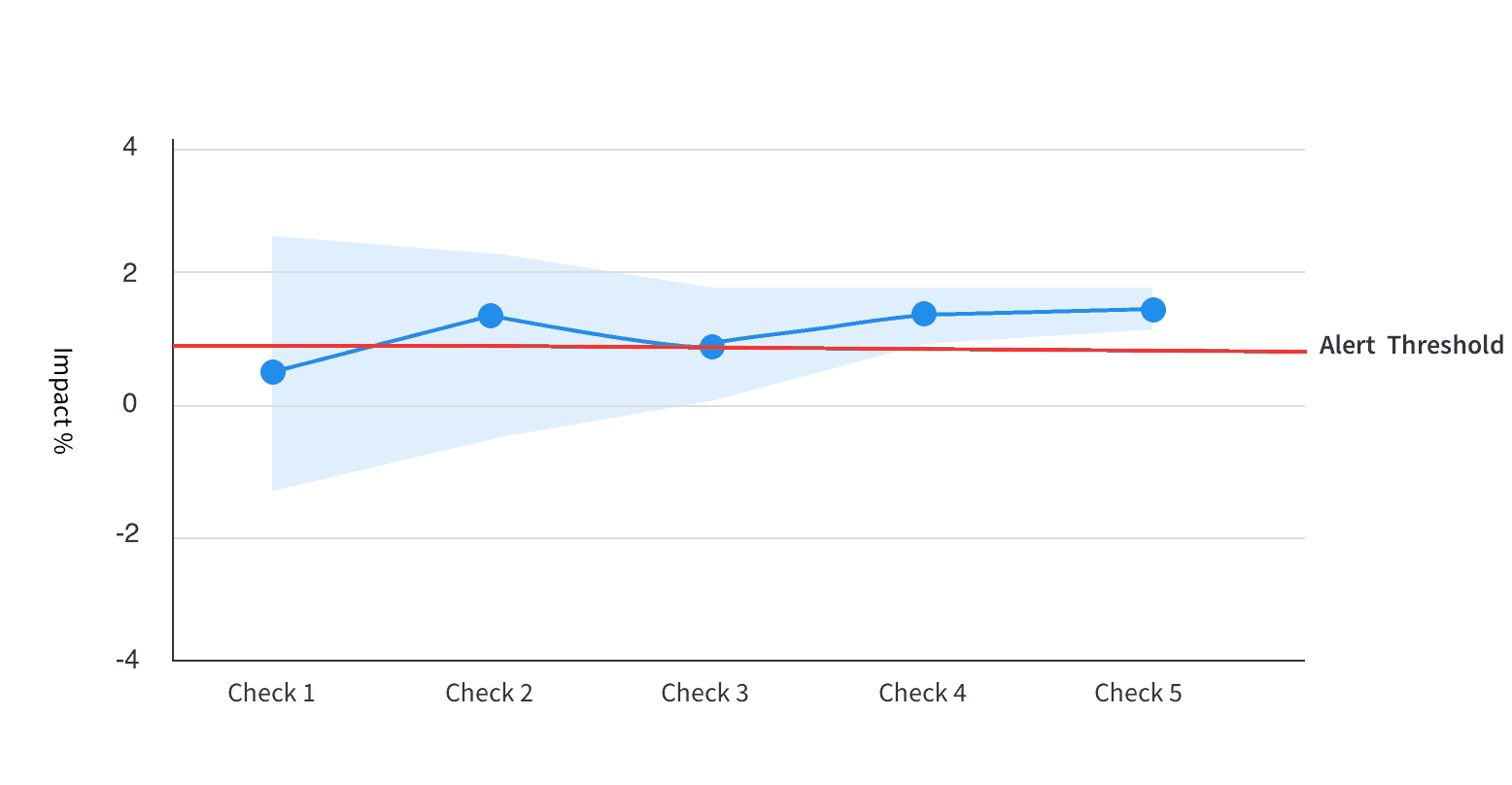
Split only alerts you if we are confident that your metric has degraded beyond your alert threshold. For example, if the results were as shown in the image below, an alert would not have fired for the first 3 checks, even though the observed impact is already above your set threshold after Check 2. The reason no alert fires in these earlier checks is because the error margin, or confidence interval, on the impact is too wide for us to be confident that the impact really is greater than your threshold. However, an alert would fire for Check 4 and Check 5.
Getting started with alert policies
Alert policies allow for automatic detection of metric degradations and the identification of the exact feature in your release that caused it. This means you can triage problems more effectively and speed up your deployment cycles overall.
Ready to get started? We have all the details you need in our docs. Don’t yet have a Split account? No worries, sign up here and we’ll get you set up!
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.
Switch It On With Split
The Split Feature Data Platform™ gives you the confidence to move fast without breaking things. Set up feature flags and safely deploy to production, controlling who sees which features and when. Connect every flag to contextual data, so you can know if your features are making things better or worse and act without hesitation. Effortlessly conduct feature experiments like A/B tests without slowing down. Whether you’re looking to increase your releases, to decrease your MTTR, or to ignite your dev team without burning them out–Split is both a feature management platform and partnership to revolutionize the way the work gets done. Switch on a free account today or schedule a demo to learn more.