The goal of every product team is to build a product that solves a problem a customer is experiencing. Beyond that, product teams strive to create frictionless, efficient, and safe user experiences that will keep users coming back. Modern product teams deliver on these goals via rigorous experimentation programs and robust A/B testing tools. In this guide, we will share how we advise our customers to approach their experimentation programs and structure their individual experiments.
It all begins with a roadmap.
The Roadmap
Often, product roadmaps are driven by the vision of a leader, the brainstorming of a team, or the feedback of a customer. While these are each excellent sources of ideation, they can also result in prioritization based on the loudest voice in the room. In his book Web Analytics, Avinash Kaushik coined the term HiPPO to refer to the highest-paid person’s opinion.
Executives and leaders will often have a wealth of knowledge and experience which drives their ideas, but which also stifles creativity and debate from other team members who may be closer to the problem. Teams can easily find themselves rutted on a particular line of thinking, weighed down by a history of incomplete projects, plans for second versions, or technical debt that might prevent them from looking outside of the box. While the feedback of customers is essential to address issues and requirement gaps, that same feedback is often limited to the behaviors that they know. After all, if Henry Ford had asked people what they wanted, they likely would have asked for a faster horse.
Now, every company is guided by measurable goals — every month, quarter, or year the team gathers to set and update their goals — but all too often those goals are driven by the roadmap. The product team will release these features on this timeline for those reasons. A project is prioritized first and then it is determined what its goals are and how they may be measured. As a result, success is simply determined by whether or not the new feature is delivered to customers.
Instead, an organization’s product roadmap should be driven by metrics first. The team targets an increase in new customer retention, in engagement with a part of the platform, or in a particular segment of revenue. It’s from those measurable goals that the backlog of ideas (collected from all of the usual sources) are reviewed and compared against. The team also has the opportunity to perform more focused brainstorming, exploring that particular problem statement and identifying novel solutions. Dedicated research can be performed about how that metric currently works, to review what has worked in the past or what problems exist in the present. When the team executes those projects, they can measure the success of those efforts against those metrics. There is the opportunity to learn from the process, to embrace new ideas, and to pivot when alternatives arise.
Too often, even “agile” organizations commit to a set of feature releases at the start of the quarter, only to end the quarter with a set of deliverables very different from their initial goals. Such flexibility is essential in today’s business environment — but when the goals change so fluidly, it becomes very challenging to measure whether success was achieved. With metrics as their target, a product organization can retain that fluidity while improving focus and having consistent movement on what’s most important for the organization’s success.
Data-Driven Decisions
When first starting out, experimentation can be an intimidating concept. You might picture scientists, or how your marketing team constantly tests dozens of hero images or calls to action. For a product and engineering team, the idea that a project they dedicated hundreds of people-hours to might not succeed in its goals is scary. It’s important to remember that an experiment is simply the process of learning.
Every change you make to your product has an impact. It may be large or small, positive or negative. An experiment does not change what that impact is, it simply gives you a way to measure it. With data, the organization has the opportunity to learn, and to build better and faster in the future.
An experiment may have a variety of goals. It may be to hone in on the best implementation of a feature. These are optimization tests, and what may come to mind when you think about experiments. It may be to find out if the change causes issues; this is a do no harm test, it validates that the new change is not worse than what came before. Often the team may simply be identifying learning from the releases they are already making, determining whether they warrant further investment.
Each iteration of the product development lifecycle is defined by two choices. The first choice is what change should be built in this cycle, and the second is when to release that change. Today, the first choice may be made during the initial roadmap planning and the second may simply be “when it is done.” By building a culture of experimentation, however, your organization can reshape the way these choices are made. The first choice, the hypothesis, will be based on the measurable goals of the organization and informed by experience. The second choice, the decision, will be informed by data and empowered by a process designed for speed and learning.
The Hypothesis
Hopefully, this talk of a hypothesis will remind you of learning the scientific method back in school. For a product team, writing a hypothesis involves simply taking the time to write down the intention behind the change, and to identify what is expected to occur as a result. This may already be part of the project specification process. By taking the time to plan out the release, the team stays informed of the intention behind each change — and the organization has a record of the plan to refer back to later. It gives you the opportunity to decide upon the metrics you wish to measure and ensure that they are configured; to establish the current baseline and make sure the data is collected appropriately.
The Decision
A common misconception is that an experiment is successful only if the hypothesis is proven. This could not be farther from the truth. The purpose of an experiment is to learn about the change. While it is always nice to learn that you were right, it is often far more interesting to learn that you were wrong — that reality behaves differently from how you expected it to be. When that happens, you begin to look for new solutions and are able to make real breakthroughs.
If a change fails to achieve its intention that does not mean that it has to be rolled back or that the project has to be scrapped. Decisions typically take one of three forms:
- We celebrate the times that we achieved or exceeded our intentions.
- We iterate on the ideas which aren’t connecting as expected.
- We obliterate the things that we find we are dead wrong about.
When forming our initial hypothesis, we should have some default action in mind. This is what you would do in the absence of any data. In science, the default action is usually to be conservative, to not publish the paper or to not release the drug. For product development, often that default action is to move forward and release the change. The team dedicated time and effort to build this new feature, so the data would need to be very convincing in order to not release that work. Even if the results are negative, the decision is usually to iterate on the feature, not to obliterate it.
Now, it is important to accept that releasing features comes at a cost: bugs will need to be fixed, customers will need to be onboarded, new employees will need to be trained. As you build a culture of experimentation you will find that having access to this data will influence how you operate. Rather than debating approaches, they can be tested. Rather than spending weeks or months on a project which may not achieve its goals, the team will measure incremental changes to justify further investment.
The good news is that any team can be empowered to learn from the changes they are already making. With experimentation, they gain the data to truly celebrate successes, to identify and stop issues, and to learn where there is opportunity to improve. Just bear in mind that not every change is going to result in a celebration. Industry leaders in experimentation report that as many as 80% of experiments run do not have the desired impact on their key metrics. If those releases were merely deployed without proper measurement, it would be easy to assume success and dive into the next enhancement for a feature that doesn’t actually deliver value — or worse, one that actively degrades the success of the business.
Metric Design
To effectively manage your experiments, test your hypotheses, and return meaningful results, you need to know what to measure and how to measure it. This is what we mean when we refer to metric design. As you may recall from the classic scientific method, correlation does not imply causation — in other words, just because two events or phenomena take place simultaneously, it doesn’t mean that they have anything to do with each other (though they may). Metric design needs to factor this in, and find a way to prevent false positives.
You create and test features towards (hopefully) positive outcomes, but you do not test your features in a vacuum. There are likely many other factors that can have direct and profound effects on performance. Some are relatively predictable, such as a surge in online traffic around particular holidays, while others come out of nowhere — a perfect example being the global pandemic. Running a scientific, controlled experiment with strong, clear metrics enables experimenters to separate the feature performance from the fluctuations of the world around them, attributing the right data to the right causes.
To this end, a randomized control trial is a useful way to look beyond correlation and find causality. This is done by testing your change with user samples — selected in a way that is free from overplanning and potential bias — and measuring the behavior of those exposed to the baseline product, and those exposed to the treatment or variant. By doing this, you distribute the effects of external factors between the two samples, and can figure out which changes in behavior are directly caused by your new feature.
This is where attribution begins. For every data point, you can identify whether users were encountering the baseline or the treatment. Then, as you plot the results of the two different exposures, patterns emerge in the distribution of data. These can be analyzed to understand how a particular feature landed with a particular user sample. Even better, they can be quantified and compared statistically to determine whether the feature has in fact led to a shift in the status quo.
Without technology to provide support for this approach, it can be a challenge to achieve consistency and repeatability, and it’s particularly difficult to scale up. For many organizations, designing experiments and defining treatment samples are manual processes, which prevents randomization and effective statistical analysis. This was the case for Television New Zealand (TVNZ), New Zealand’s foremost public broadcaster; the company runs the popular TVNZ On Demand streaming platform, and as the team tested new features for their audiences, they knew they needed better technology to ensure random sampling and statistical rigor were built in.
Statistical analyses are the cornerstone of A/B testing, and play a vital role regardless of whether your feature is released or not. They can prove if a bug was really fixed, if a new refactor is more performant, or if a feature is actually providing value to customers. But above all, statistical analyses help you delineate correlation from causation, so you can apply the right results to the right metrics.
Overall Evaluation Criteria
What are the most meaningful metrics? To start, you should have an Overall Evaluation Criteria (OEC). This is the most important, foundational metric that your experiment is designed to improve. Generally, the OEC supports and aligns with the overall goals of your organization, and there are three key properties that it must have in order to be effective:
| Sensitivity | Directionality | Understandability |
| Even small changes in user satisfaction or business outcome should move the needle for OEC metrics, making them observable and measurable. | The measurement should be straightforward, moving consistently in one direction as the business value increases, and the opposite if it decreases. | If there is a high degree of sensitivity and directionality, as well as defined targets or objectives, then the OEC should be clear to everyone. |
Determining an Overall Evaluation Criteria is easier said than done. Take, for example, the dual need for sensitivity and directionality. Your metrics need to be responsive to short-term results so that you can measure and prove your progress — but will that progress continue as you realize your longer-term business goals? Or will it get to a point where user experience degrades? All of this has to be factored in as you devise your metrics — hence the need for understandability — and you may have to make several tweaks before you get them right.
Feature Metrics
While the OEC may be the most important metric holistically, lower-tier feature-level metrics deliver the most immediate and impactful value as you conduct your tests. Feature metrics provide feedback on how a variation in your product or program is being received by end users. Examples could include click-through or scroll rates, or other inputs that are relevant to a specific team and target. Like the OEC, the best feature metrics are sensitive to small changes and directional in their measurements.
| Tier 1 | Tier 2 | Tier 3 |
| Includes the OEC and a handful of other metrics with executive visibility. Any impact on Tier 1 metrics triggers company-wide scrutiny. | Critical for singular divisions within a company. They measure specific business outcomes, so guardrail metrics are often of Tier 2 importance. | Typically consists of the feature metrics monitored by engineers and project managers during an A/B test. Tier 1 only concerns the localized team. |
One of the biggest challenges when designing effective feature metrics is basic human nature. We all want to be right, and we all want to be successful (and we all only know what we know). These impulses can create a risk of building confirmation biases into our experiments even when we have the best of intentions, so that the tests tell us what we want to know rather than what we need to know, with results that seem to reinforce what we already believe. Or we might be predisposed to wishful thinking, skewing the interpretation of test results — usually unconsciously — towards the most reassuring outcome. If this happens, valuable time and resources will be wasted, with false signals leading to false starts.
The greatest way to prevent yourself and your team from knowingly or unknowingly “gaming” metrics is to have rigorous processes and principles in place to guide the design, execution, and analysis of your experiments. This involves the implementation of guardrail metrics.
Guardrail Metrics
Guardrails are an alternative set of metrics that alert you to negative side effects that your experiments may cause — whether you want to see them or not. Good guardrail metrics should be sensitive and directional, like the OEC and feature metrics, but they don’t need to tie directly to the business value. Rather, they should focus on factors that should remain stable, and not degrade, as your experiment progresses and you pursue the OEC. We can therefore categorize two different types of guardrails:
| Performance guardrails such as page load times and app crashes, which pertain to your specific product, feature, and test. | Business guardrails such as unsubscribe rates, which help demonstrate the broader ramifications for the organization. |
While it is fairly obvious when something goes seriously wrong, guardrails help you observe more subtle problems so that you can mitigate risks and costs. Robust monitoring is necessary, and you need to set practical thresholds around when to press the kill switch to end a troubled experiment.
| Should You Automate Your Kill Switch? The question of whether to automate your kill switch is complex, and the answer is different for every company, every team, and every experiment. If you have a history of app crashes when you launch new features, or if your feature impacts critical business flows, then automation could be your best bet at preventing serious problems. Automated kill switches are also a good safeguard for releases that are designed to be backward-compatible so that rollbacks will not cause further problems when the newer code interacts with older systems. But there are issues with automatic kill switches. As mentioned already, correlation does not imply causation, so automated switches can terminate features even when the issue they detected was due to something entirely different. Automated kill switches can also lead to challenges when features have been live for a long time and are burdened by technical debt. If the switch activates, it’s difficult to predict the errors it could cause, since everything around the legacy feature has changed. |
Teams dread the possibility of new features causing unforeseen problems for their end users. At Speedway Motors, a leading producer and supplier of top-quality automotive parts with millions of visitors each month, there was so much anxiety around new feature releases that engineers were on standby at all hours for emergency hotfixes or rollbacks. That changed when they brought in feature flags to control the blast radius of their A/B tests and end them right away if something went wrong.
This just goes to show how much your metrics matter. Understanding and validating your OEC, feature metrics, and guardrails are vital to successful, ethical product experimentation.
Product Experimentation Lifecycle
Organizations with mature and deeply embedded cultures of experimentation often take a decentralized approach to testing, whereby any member of any team is empowered to design, launch, and terminate a new feature. It’s more common for experiments to be centrally managed by experts such as developers and data scientists, or overseen by a designated center of excellence. As a general rule, it makes sense to start centralized and apply the following advice before scaling out to a distributed approach.
Design With an Intent To Learn, Not Confirm
Perhaps the most important part of the product experimentation process is learning. If you develop products, or if you design experiences, then humility is essential. In order to find the best solutions, you first have to begin by admitting that you do not have all the answers, then build your approach with openness, creativity, and curiosity. If you do this, you’ll probably use a more robust methodology to understand the results of your experiment and quantify the KPIs associated with your feature release — benefiting your business, and no doubt impressing your executives and senior managers.
An even more compelling advantage of cultivating a learning mindset is that it helps you design better experiments that focus on fostering knowledge and strategies for the long term, as opposed to demonstrating quick wins. An example is the painted door test. Rather than spending time and resources building a fully fledged feature in hopes that users will like it, you design a simplified proxy with the purpose of researching customer behavior. In short, you build a painted door without actually having to put a room behind it, and see how many people knock on it. This tells you whether or not building the full feature is worthwhile.
Finally, a learning mindset empowers you to map out more robust statistical hypotheses, and perform the data-driven hypothesis tests and statistical analyses that will deliver meaningful results. Here are some of the factors you need to consider:
| 1. | Before you conduct your randomized control trial, you need to select the right randomization unit for your experiment. In many cases, your randomization unit will be the users who may receive the baseline version of the product or the new treatment, but there are alternative randomization units that you could analyze — for example, sessions, unique device IDs, or page views. |
| 2. | Depending on the product or service you provide, it might be necessary to restrict an experiment to those segments of the population that will reliably take advantage of the new feature. Targeting can be used to limit your test to certain customer profiles, locations, websites, or technology interfaces, such as mobile or desktop. |
| 3. | When laying out a statistical hypothesis, it’s helpful to perform a power analysis. This allows you to calculate the minimum sample size you need to detect whether or not your experiment has led to a measurable effect in user behavior. You also employ a power analysis to calculate what the minimum effect size needs to be in order to be noticeable within your sample. |
| 4. | If you have effective feature flagging capabilities, then you also have the option of conducting several A/B tests at once. After all, sequential testing can entail lengthy timelines and strained resources; but if you structure your tests effectively, then you can run simultaneous experiments without any negative effect on the quality of your results. |
Ideate and Prioritize
Ideation for your feature tests begins by bringing the right people and perspectives to the table, from multiple facets of the business. As you prioritize your next slate of experiments, here are some focus areas and key stakeholders who should be involved in those ideations and conversations:
- For product teams, as well as UX and UI designers, optimization at the feature level demands frequent A/B testing to ensure frictionless customer experiences.
- For marketing teams, driving impressions and conversions is constantly top of mind, and it’s fascinating to see how minor alterations can drive major engagement.
- For management and growth teams, experiments should be designed and prioritized according to the company’s goals, and top-tier metrics such as the OEC.
Launch and Observe
Once you know what metrics will be tracked and how your experiment will be structured, the next stage is to execute it. Here are some important considerations as you launch your sequential or simultaneous experiments and put your new feature into production.
Include Do No Harm Tests
Exercise caution when experimenting, especially when testing new features for well-established products. Similar to putting guardrail metrics in place along with your feature metrics, it’s a good idea to incorporate do no harm tests into your experiment design in the early stages, helping to ensure that new releases are not having a negative effect on existing metrics and resulting in worse user behaviors.
Do no harm tests can be critical, because no matter how fail-safe an experiment may seem, or how small the feature release, you never know when a breakdown could occur. You may have heard the story of the lawyer who was so confident in his office building’s shatter-proof windows that he had developed a gag where he threw himself against the glass — until the unfortunate day when the whole window frame gave away. Do no harm tests and guardrail metrics are there to protect you on the days when the window frame falls out, providing peace of mind before an unforeseen glitch can become an unmitigated disaster.
Balance Speed, Quality and Risk
At LinkedIn, their team proposed that effective experimentation strategies balance speed, quality, and risk of the decision that is made. Speed refers to how quickly you reach a decision. The faster you decide, the faster you start delivering value. Quality is not whether the change is bug free, but represents whether this decision is the right one. Whether the change accomplishes what we expect it to. Risks come in the form of bugs, performance issues, and security holes — but also the risk of having worse results than what was replaced.
Use Progressive Delivery
Traditional deployments maximize speed; the code is immediately active, but it makes the decision blindly and it exposes the entire system to any negative ramifications. On the opposite side of the spectrum, never changing your code minimizes the risk related to change, but also has a velocity of exactly zero. In many cases not taking action can be your worst decision.
Progressive delivery seeks to strike a balance between these factors, making the best decision in the fastest possible time, while minimizing the impact of negative effects. With progressive delivery, deploy and release of new code is divided into four or five phases, with each phase protecting and informing the next step in the process:
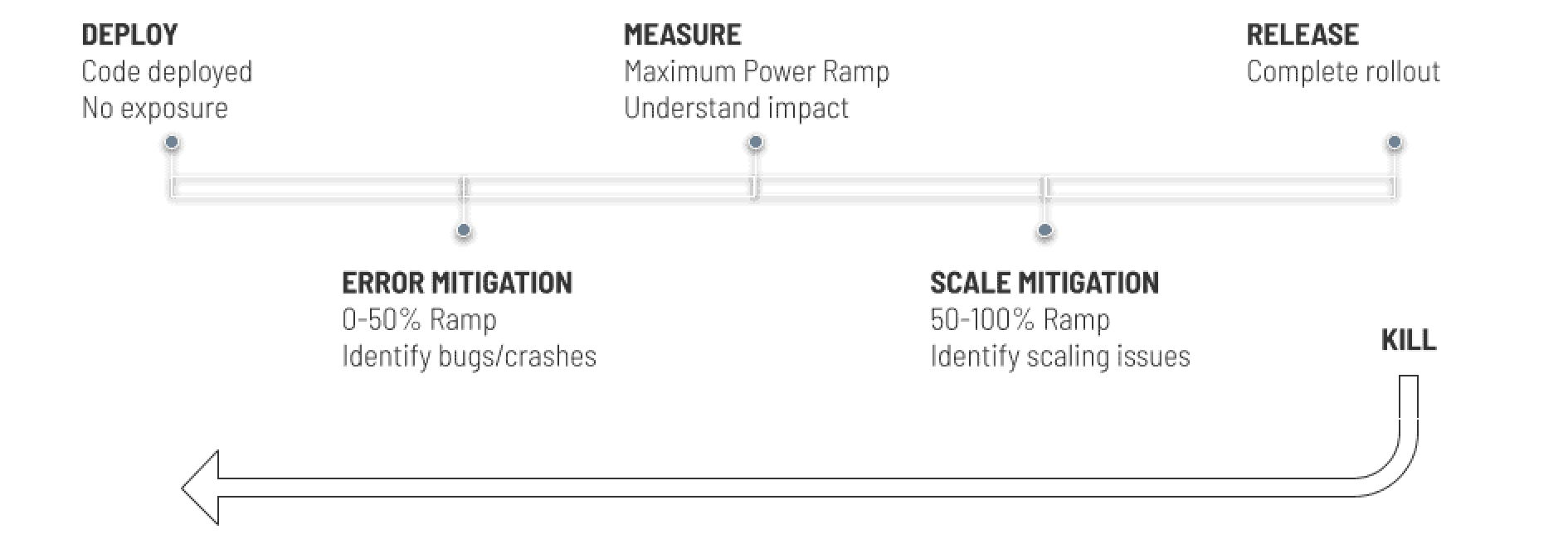
Deploy
First, the code is deployed behind a feature flag that has been turned off. This ensures that the change is not yet exposed to anyone, eliminating deployment risk.
Error Mitigation
Next, error mitigation is accomplished with testing in production and canary releasing. Testing in production allows developers, testers and internal stakeholders to verify functionality one last time in the actual production environment before ever exposing it to customers. Canary releasing exposes the change to a small percentage of customers to identify edge cases that may have been missed in prior testing.
Measure
Next, we move to measure the impact of the change. To collect true insights, the rollout is best served by dividing traffic evenly between variations. Known as “maximum power ramp,” this 50/50 distribution maximizes the size of each sample, increasing the quality of your decision in the fastest way.
Scale Mitigation and Holdbacks
If the results look good and the team decides to launch, typically the next step is to simply release the feature fully and retire the old code. Certain changes, however, may introduce additional load onto systems or require support to be released successfully. Continuing to ramp from 50/50 to something closer to 70/30 or 80/20 allows the team to identify scaling issues and to roll out necessary infrastructure changes or training to ensure success.
In some cases, the impact of a change may differ over long periods of time or based on particular seasonal concerns. While not common, to measure these cases, a small portion of traffic can remain on the old behavior allowing for those effects to be measured and providing further learnings for the team over time. This population is known as a “holdback” cohort.
The Kill Switch
If an issue surfaces at any point, the release can be stopped. All traffic can be routed back to the prior experience and the team can take the time to address the issue, either by fixing problems, iterating on the experience, or making the decision to stop the project and record those learnings for future use.
Test Your Tests: A/A Testing
From time to time, it’s a good practice to confirm that your test infrastructure is not itself introducing any bias or anomaly by performing A/A testing. In an A/A test, you expose the same experience to two populations chosen by your targeting mechanism and observe your metrics as you would during an A/B test. Since you are delivering the same experience, you should see no significant difference between either side of the A/A test.
A/A tests let you verify that your users are split according to the right ratios, that your experiment is yielding the data you need without unnecessary risks, and that there are no apparent variations or biases between your samples. In short, you should never neglect to test your tests.
Conclusion
The process of experimentation never ends. Rather, investments you make in better understanding your business have a flywheel effect: As you conduct experiments, you learn to ask better questions and add new metrics that quantify the impact of changes.
When automated, these metrics are available without further human effort for other experiments you run concurrently and in the future. Once a guardrail metric is in place, it can function as a 24/7 automated monitoring and alerting layer, ever on the lookout for unforeseen consequences.
By laying the right foundation based on the time-tested principles in this guide, you will increase your odds of achieving greater predictability, repeatability, and scalability for your experimentation practice.
In the end, your customers are the final weighing mechanism for the value of your efforts. Experimentation is the surest way to observe your customers in an unbiased way, focusing your efforts on facts, rather than opinions or habits.
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.
Switch It On With Split
Split gives product development teams the confidence to release features that matter faster. It’s the only feature management and experimentation solution that automatically attributes data-driven insight to every feature that’s released—all while enabling astoundingly easy deployment, profound risk reduction, and better visibility across teams. Split offers more than a platform: It offers partnership. By sticking with customers every step of the way, Split illuminates the path toward continuous improvement and timely innovation. Switch on a trial account, schedule a demo, or contact us for further questions.