
Experiments can come in all shapes and sizes, and every test is different. Hence for most organizations, the right balance of risk vs. velocity, or precision vs. breadth of insight, can vary on a case-by-case basis.
To support the wide variety of use cases and situations, we have introduced the ability to customize your experiment settings individually for each experiment. With this additional flexibility, you can ensure your experiments are designed and analyzed in the way which best suits the case at hand.
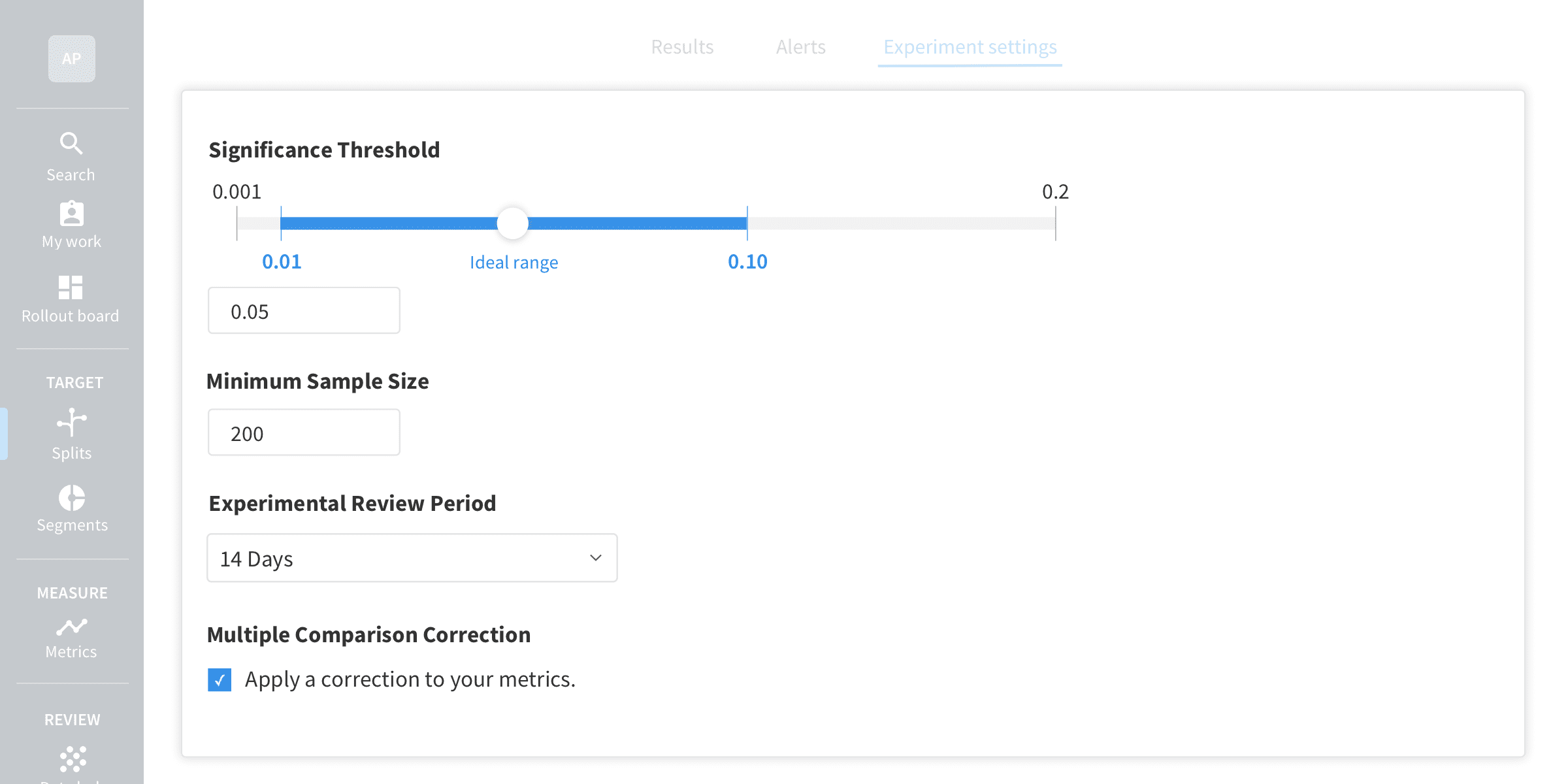
Set Your Risk Tolerance
There are several trade-offs and choices to make when it comes to analyzing the results of an experiment. For example, a stricter significance threshold will give you more confidence in your conclusions and a smaller chance of coming across false-positive results. However, this would come with the disadvantage of needing a larger sample size before an impact can be detected, often requiring you to wait for a longer period.
For this reason, the best significance threshold to use depends on your answer to questions such as:
- Do you value speed overconfidence?
- How costly would a false positive result be, compared to the opportunity cost of missing out on detecting an impact that is there?
- How long are you willing to wait before making your decisions?
These questions often come down to understanding the level of risk you are willing to take with the test. It is important to note that there is no right or wrong answer here. For example, suppose you are testing a significant redesign of your product. In that case, you may reasonably require high accuracy and confidence in the results and be happy to wait for a longer time for the experiment to run to achieve that. On the other hand, for a smaller-scale test such as a copy change on a low-traffic area of your product, you may consider it a low-risk decision and value speed over high accuracy.
The significance threshold is not the only lever you can pull to adjust the level of risk in your tests. At Split, we also allow you to choose whether to apply multiple comparison corrections to your results and specify the minimum number of samples needed before statistical comparisons are run. Each of these settings impacts how your experiment is analyzed, and the optimal settings can differ from one experiment to the next. The ability to customize your settings at a test level can unlock new use cases for some tests, such as testing on small sample sizes or getting quick insights, without affecting the rigor and accuracy needed for your other tests.
Reflect the Optimal Design for Each Experiment
Experimental design is a vital part of the experimentation lifecycle. In the planning and design stage, it is recommended to decide in advance how long your test will run for and how it will be analyzed.
For example, while a 14-day test duration may make sense for most of your experiments, there may be situations where it makes sense to run for longer or shorter periods. If you are running a test on a low-traffic portion of your product, you may well find that you need to run your test for longer to reach significance than if you were testing on a high-traffic page. These variations in the experimental design can now be reflected in your customized settings.
Customize Your Experiment Settings
You can customize the settings for each test you run directly on the split (experiment) page. To customize settings for your experiment, sign up for a 30-day free trial today.
Learn More About A/B Testing and Experimentation at Split
While Split gives you a great degree of control over your experiments, such as the customizable statistical settings we covered above, the platform also has built-in experimentation best practices so you can produce statistically rigorous results without having to be an expert. In addition, we offer tons of tips and resources on our website.
- Experimentation in Split: Make Your Events Work for You!
- Track Unlimited Metrics with the Same Statistical Rigor
- How to Experiment During Extreme Seasonality
- The Difference Between A/B Testing and Multivariate Testing
And as always, we’d love to have you follow along as we share new stories. Check us out on YouTube, Twitter, and LinkedIn!
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.
Switch It On With Split
Split gives product development teams the confidence to release features that matter faster. It’s the only feature management and experimentation solution that automatically attributes data-driven insight to every feature that’s released—all while enabling astoundingly easy deployment, profound risk reduction, and better visibility across teams. Split offers more than a platform: It offers partnership. By sticking with customers every step of the way, Split illuminates the path toward continuous improvement and timely innovation. Switch on a trial account, schedule a demo, or contact us for further questions.