
Customers today use a myriad of tools to measure and understand their customer’s experience, capturing data across solutions such as Segment, Google Analytics, Adobe Analytics, Pendo, Amplitude, NewRelic, Mixpanel, and many others.
We built Split’s experimentation platform with this fundamental assumption: the data you capture to measure and understand your customer experience is collected across many touch points by a variety of tools. It is critical that any tool you use to release feature functionality and measure its impact can capture data from these multiple touch points.
Automatic event attribution for scalable experimentation
Unlike other experimentation platforms, which require additional work to join feature-treatment assignments to external track events, Split can automatically consume and intelligently attribute track events to your experiments.
Learn more about sending track events to Split.
With this architectural advantage, the Split platform can receive data from any source, automatically identify the sample population using split impression events, and, using event attribution logic, intelligently attribute those events to each sample based on targeting rule and treatment.
How Split attributes events to impressions
To understand Split’s attribution, let’s look at a simple example.
In most scenarios, the treatment a user receives will not change for the course of the experiment or until the version of the experiment changes.
In this case, Split identifies when the user first saw the treatment and attributes all events within 15 minutes of this first impression. If an event occurs more than 15 minutes after the user’s first impression, Split won’t attribute the event to the experiment on the metrics impact page. This same logic applies to the end of the experiment. There is a 15 minute buffer for events to be received after a treatment changes before we run the final calculation. Then the metrics impact page is frozen for that version.
Below is a diagram that illustrates this attribution following a single user’s activity:
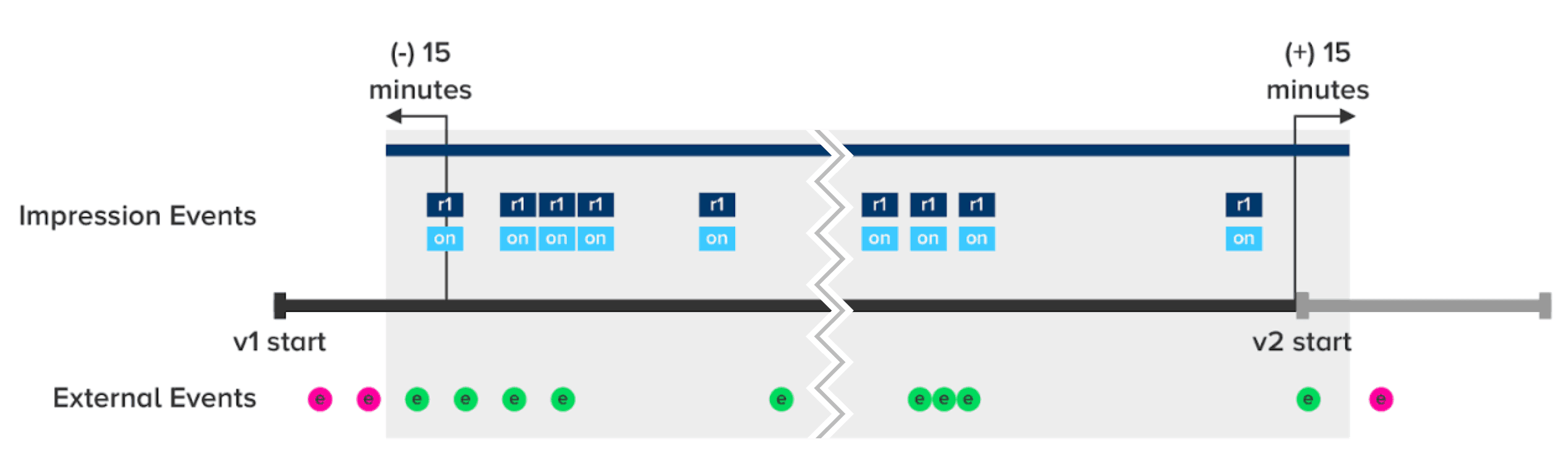
We’ll use this example to follow how Split attributes events when a user’s rule and treatment do not change throughout the version.
e represents an external event, such as a click event. These events appear across the bottom of the experiment timeline.
r1 and on are a representation of the user’s impressions containing the rule (r1) and the treatment (on). At these points, Split is deciding whether the user is bucketed into a certain treatment based on the targeting rule you’ve defined. In this example, all impression events in the timeline are for the same treatment and targeting rule.
The example in the timeline diagram shows the user’s activity in your application. When calculating metrics, Split will include the shaded region — the events from 15 minutes before the user’s first impression to 15 minutes after the end of the version. Events highlighted in pink are relevant to this example.
You can learn more about Split’s attribution and exclusion rules in our documentation.
How Split automatically excludes users from analysis
When covering attribution, it is also important to understand what causes a user to be excluded from the analysis. In Split, there are two primary scenarios when the platform will automatically remove the user from the analysis.
The first is the result of the user changing treatments within a particular rule. If a user is exposed to multiple treatments within a split targeting rule, you would want to disqualify the user from the experiment and exclude their data when looking at your metrics. Otherwise, the user’s data would then be applied to both sides of the experiment, in both treatments, and would cloud your results.
The second is a result of moving rules more than once in a particular version of your experiment. Split’s engine allows users to move between rules and treatments once within the same version. If a user is frequently moving between versions and treatments, there may be an issue with your experiment and how you are targeting your users. To be safe, and not provide bad data, Split cautiously removes the user and their data from the analysis.
What’s changed?
Users are now allowed to move between targeting rules once in a particular version. Before this change, a targeting rule change caused users to be removed from the sample.
This allows for the targeting of customers using an attribute that when changed will result in a different treatment and targeting rule. The most common example from our customer base is targeting ‘trial’ users with a feature focused on driving them to become a paid customer.
If user.plan is in list trial then 100%:on 0%:off
Once the user becomes ‘paid’ the feature is no longer visible, and the treatment moves from on to off.
These changes are a reflection of lessons learned in experimentation, and we look forward to continuing to enhance our experimentation capabilities all while making it simpler for your team to conduct its experiments with the data they are already collecting.
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.
Switch It On With Split
The Split Feature Data Platform™ gives you the confidence to move fast without breaking things. Set up feature flags and safely deploy to production, controlling who sees which features and when. Connect every flag to contextual data, so you can know if your features are making things better or worse and act without hesitation. Effortlessly conduct feature experiments like A/B tests without slowing down. Whether you’re looking to increase your releases, to decrease your MTTR, or to ignite your dev team without burning them out–Split is both a feature management platform and partnership to revolutionize the way the work gets done. Switch on a free account today, schedule a demo, or contact us for further questions.