
This is one post in a series about managing the breakup of a monolithic architecture into a small service. In the first post of the series we looked at some fundamental techniques which allowed us to perform this sort of broad architectural shift as a series of small, safe steps. We started off by looking at an intentionally simple example—extracting a small, stateless service from a monolith. In this post we’ll look at a more challenging example, extracting a service which is backed by persistent state which initially lives in a monolithic shared data store.
To examine this more complex scenario, we’ll imagine that we’re extracting a Product Catalog from an e-commerce system. This product catalog is responsible for tracking information about all of the products available for sale by the system.
The challenge of extracting stateful services
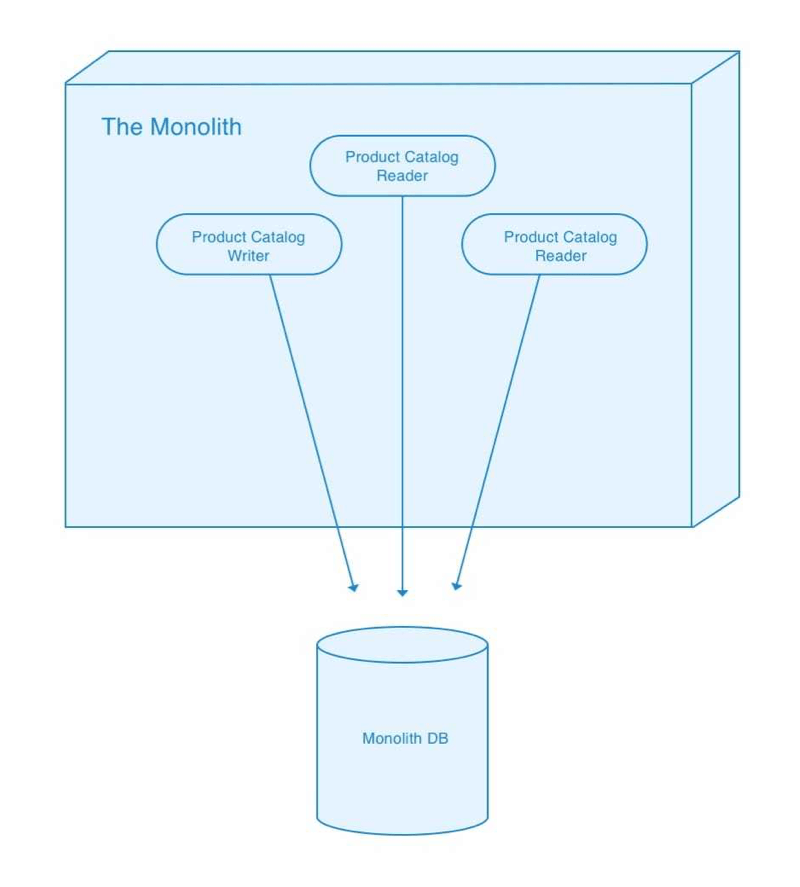
Extracting a stateful service from a monolith is hard. Monoliths tend to use a single shared datastore to manage information for all the functional areas within the monolith. At the data layer, there is often no modularization in play. It’s very common for integration of data from those different functional areas to be performed directly — typically via a database join.
Let’s look at a concrete example. Our e-commerce system has a Previous Orders page which pulls in details about each product in an order. As a monolithic system it assembles the data which powers that page using an ORM which internally performs database joins across an Orders table, a Products table, etc. This approach is very convenient and cheap to implement, but it also bypasses any sort of formal interface between different business domains within our e-commerce system. The interface for the Product Catalog domain is essentially reduced to the current database schema. This tendency towards low-level integration across conceptually distinct domains is a common theme in monolithic systems. It’s just too tempting to reach for a DB join without realizing that you’re tunneling across different areas of your system without any sort of defined API.
Extracting a defined business capability out of the monolith and into an external service will force the replacement of some of these database-level integrations with more formal service integrations. Unpacking these fine-grained integrations is the hard work in extracting a stateful service. It can come as a surprise to realize just how tightly coupled different parts of the system are via database joins.
Segregating querying state vs. updating state
As we extract our Product Catalog capability we’re going to introduce two distinct interfaces. One will be used to update the Product Catalog while the other will be used to query the Product Catalog. Segregating stateful integrations in this way will be key in achieving a controlled, incremental migration to an external service. It will allow us to maintain synchronized state across two distinct data sources for a period of time while we migrate from our internal implementation to an external service.
Creating these two distinct interfaces will allow us to perform our migration as a Parallel Change, in the following sequence:
Step 1: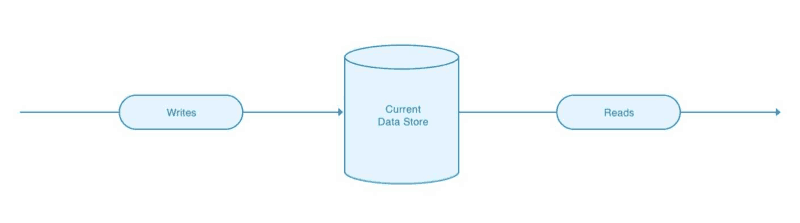
Step 2: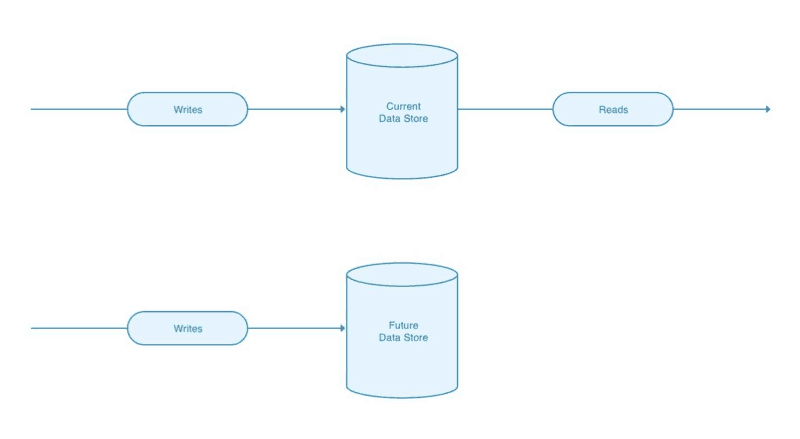
Step 3:
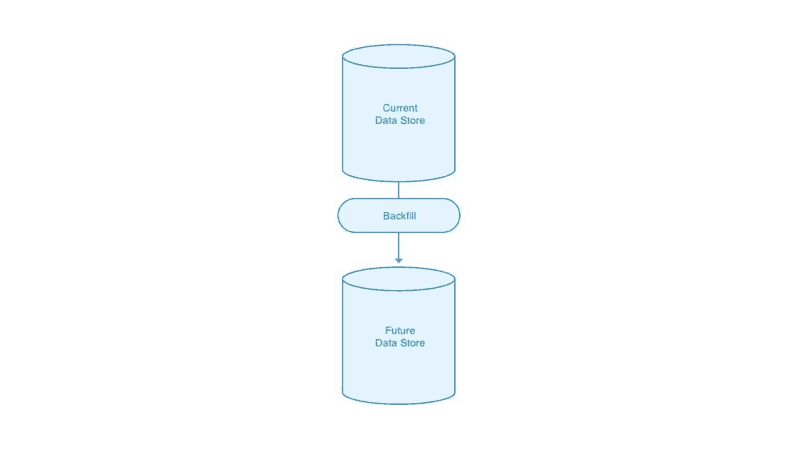
Step 4: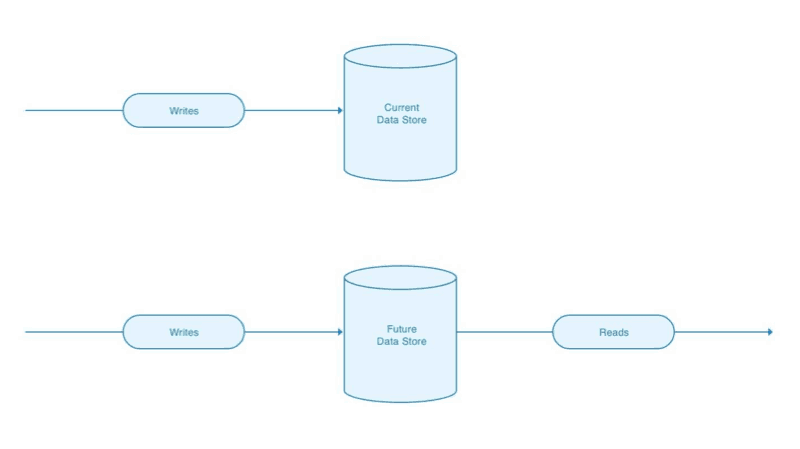
Step 5:
This segregation of queries vs. updates follows similar principles to CQRS. However, our motivation in introducing these two distinct interfaces is simply to allow us to migrate state out of the monolith in a controlled manner. We won’t be going as far as we would if we were fully embracing CQRS.
Extracting a Product Catalog
Here’s the plan for extracting the Product Catalog capability that currently lives inside our monolith.
- Gather all Product Catalog reads behind a Query Facade
- Gather all Product Catalog writes behind an Update Facade
- Introduce an initial external Product Catalog service, implementing update functionality
- Introduce an Update Duplicator which routes Product Catalog writes to both internal and external implementations
- Backfill external Product Catalog with existing historic data, if necessary
- Implement query functionality in our external Product Catalog service
- Introduce a Query Toggler which can route a Product Catalog read to either internal or external implementation
- Migrate all reads over to external store, controlled by feature flagging infrastructure
- Clean up — remove internal implementation along with read toggler and update duplicator
Let’s get started!
Introduce a Query Facade
Our first step is to introduce a Query Facade within our monolith which represents a coarse-grained interface for querying the Product Catalog for information. With this Facade in place we then modify existing query-based integrations to use that Facade. For example, where we had been including product details in our Order Details page via a database join we’ll move to including the product details via a call to this new facade.
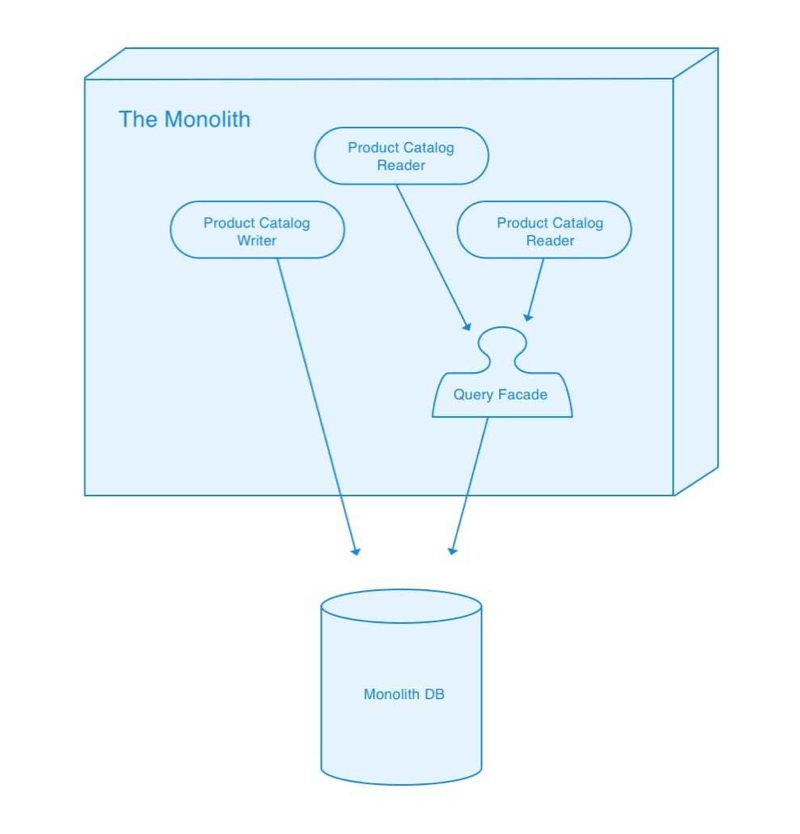
As discussed above, this internal restructuring can turn out to be quite a lot of work. Keep in mind that the Query Facade you introduce needs to implement an API that can be satisfied by an external service. Keep those distributed computing fallacies in mind!
Introduce an Update Facade
Next we perform a similar restructuring for integrations which update the product catalog. We introduce an Update Facade and then modify all code which makes changes to the product catalog to use that new update facade.
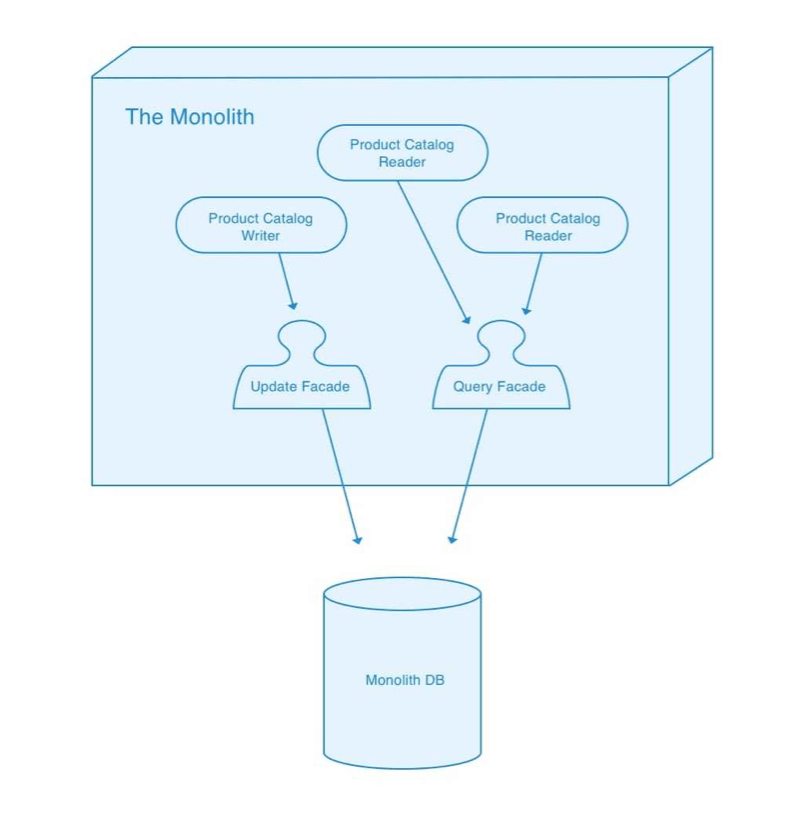
In this particular example there are likely to be more query integrations in our monolith than update integrations. With other stateful functionality — for example a Shopping Cart service — the opposite would be the case.
Introduce an external service which supports updates
We now start to build out our new external Product Catalog service. It only needs to support Update functionality for now, since our initial focus will be on ensuring that any updates to the product catalog are sent to both the live monolith implementation as well as to our nascent external service. We also follow our standard practice of introducing a second update facade which proxies updates through to our external service.
Route duplicate updates to our external service
Now that we have an external service which can receive updates we can introduce an Update Duplicator. This duplicator implements the same interface as the update facade. It is responsible for proxying update requests through to both the internal and external update facade. We modify clients of the internal update facade to now use the duplicator facade instead.
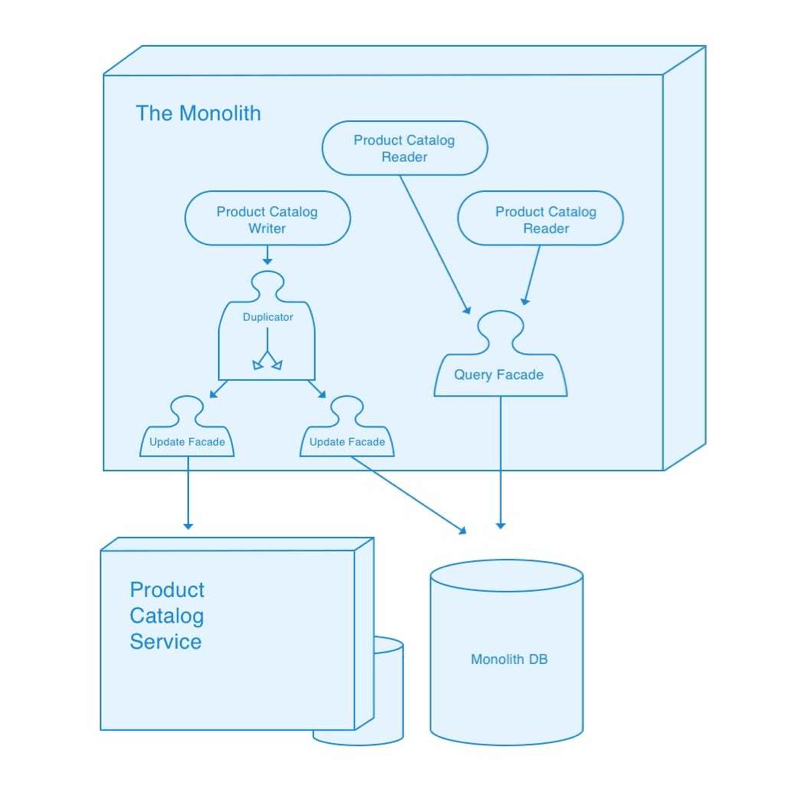
Backfill existing data, if needed
We’re now sending all updates to the product catalog through to our new service, but we will likely also need to backfill the service’s data store with information about all the existing products in the catalog.
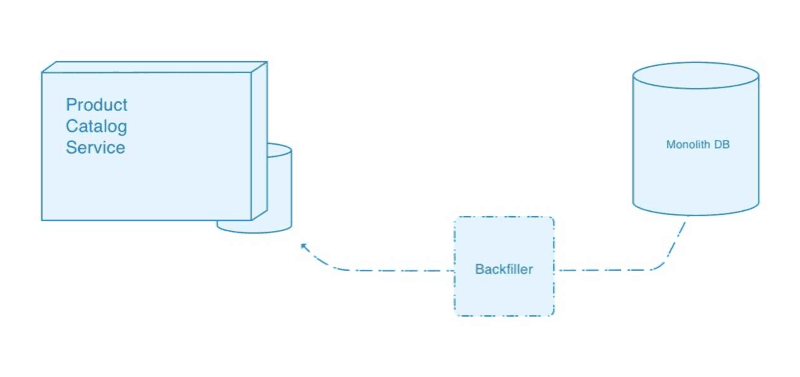
We could elect to perform this initial backfill before putting the update duplicator in place, but we would still need to do a second backfill in order to catch up with any updates that were made between that initial backfill and the duplicator going live.
Build out Query functionality in our external service
Next we’ll implement the read side of our external Product Catalog, along with a second query facade in the monolith which routes read requests over to the service. At this point our external service should be at feature parity with the internal Product Catalog. We are getting close to deleting code!
Introduce a Query Toggler
Our external Product Catalog is now feature complete, and is tracking the same state as our internal implementation thanks to our Update Duplicator. We are now ready to start treating it as the source of truth for some queries. We introduce a Toggler which implements our query facade and which will route some queries to our external query facade, based on feature flag configuration.
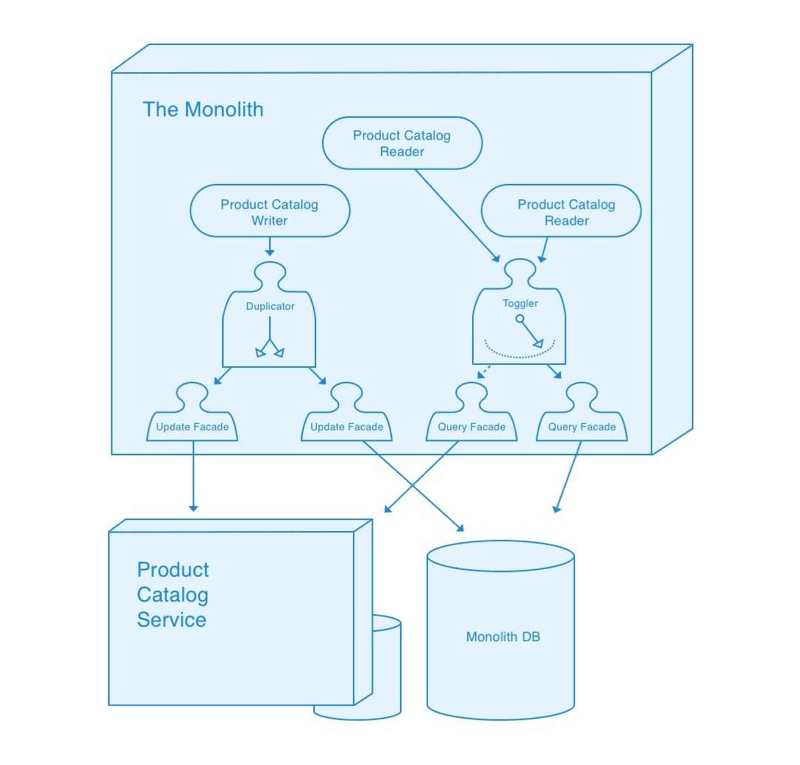
Migrate queries
With our query toggler in place we can start to migrate Product Catalog queries over to the new external service. Clients of the product catalog remain untouched during this migration — they simply make calls to the query toggler. Our feature flagging infrastructure is responsible for deciding which calls are satisfied by our legacy internal implementation and which are satisfied by our new service. We start by sending a small percentage of “canary” requests to the new service. As we gain confidence we might dial that up to 5%, 25%, 50%, until eventually all queries are being serviced by our new implementation.
During this migration we continue to route all updates to both implementations (thanks to our update duplicator). This means both systems should give consistent answers to queries. If we are feeling particularly risk-averse we can use a variant of the toggler where queries are routed to both implementations and compared, to help gain confidence in the consistency between our two data stores.
Finalize the migration
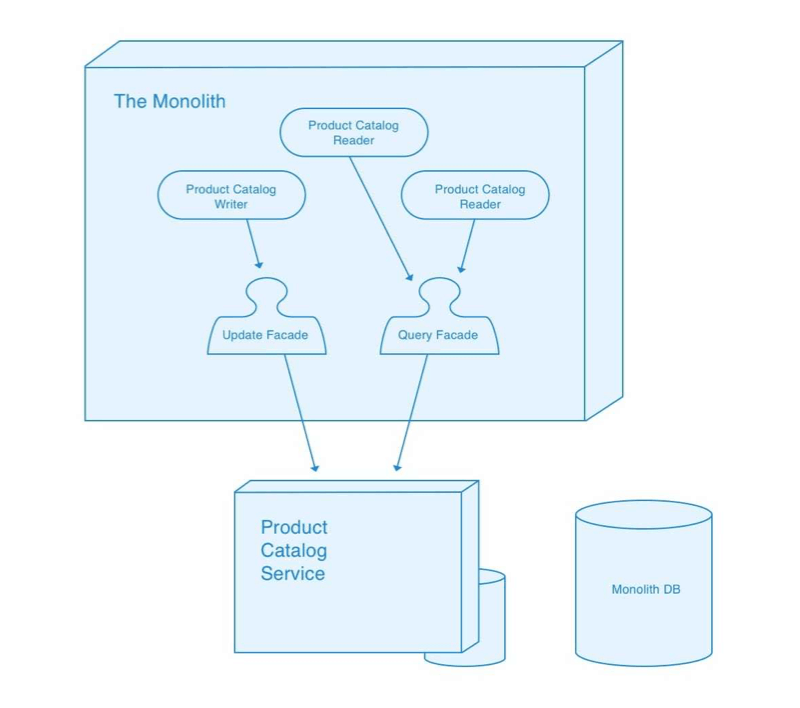
Once our query toggler has sat at 100% for a while and we are confident in our new Product Catalog service it’s time for the fun part — deleting a ton of code!
We update clients of the product catalog to be hard-wired to the external query facade and external update facade. We delete our update duplicator and our query toggler. Most importantly we delete our internal facades and drop the table in our monolithic data store that powered them. We conclude with a team trip to the local ice cream store to celebrate.
Boarding a row boat
When boarding a row boat there’s a precarious moment where one foot is in the boat and another is on the dock. It’s wise to avoid staying in this transitional state for any length of time. Moving decisively from one stable situation to the next is the name of the game. This is also true with an architectural migration where the transitional state involves straddling multiple data stores — it’s a precarious situation that you want to get past ASAP.
While straddling multiple data stores you are at risk of your data getting out of sync, resulting in a lot of time wasted on confusing bugs or worse, causing your users to experience inconsistent data. By their nature these data stores are persistent. A bug in the way your new implementation maintains state may lead to corruption that you can’t roll back from. You will need to exercise a little more caution in executing these stateful service extractions than you might for a stateless service where in the worst case you can just roll back to the old implementation while you clean up the quality issues in your new service. Measure twice and cut once, as they say.
Succeeding in a stateful service extraction
As discussed previously, the hardest part in extracting functionality from a monolith isn’t the actual extraction, it’s doing the internal re-organization within your monolith which enables a decisive, orderly migration. There will be a strong temptation to avoid this tricky work and instead build a new service which integrates against your existing monolithic data store. Resist this urge — it is almost always a terrible idea! The big win in extracting services is in decoupling different areas of your system by defining coarse-grained boundaries between them. A database-level integration will not achieve this goal. You also open yourself up to a whole new set of challenges, like managing database schema migrations across independently deployable artifacts.
The critical part of succeeding in this type of migration is in having a clear plan for moving through the transitional phase where you are keeping multiple data stores in sync, and then executing on that plan. Getting caught straddling the two stores for an extended period of time is a very uncomfortable and costly situation for a team to find themselves in.
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.
Switch It On With Split
The Split Feature Data Platform™ gives you the confidence to move fast without breaking things. Set up feature flags and safely deploy to production, controlling who sees which features and when. Connect every flag to contextual data, so you can know if your features are making things better or worse and act without hesitation. Effortlessly conduct feature experiments like A/B tests without slowing down. Whether you’re looking to increase your releases, to decrease your MTTR, or to ignite your dev team without burning them out–Split is both a feature management platform and partnership to revolutionize the way the work gets done. Switch on a free account today, schedule a demo, or contact us for further questions.