
Last week we walked The Path To Progressive Delivery. This week, we go deeper. What goals can we meet with the Four Shades of Progressive Delivery?
After you read or watch this week’s episode, you will be better equipped to choose a Progressive Delivery approach that works for you. My goal is to provide guideposts for the journey as you consider ways to increase the velocity, impact, and sustainability of your software delivery practices.
Let’s jump in to “Safe at Any Speed” Episode 06!
Quick Review: Why The Emergence of Progressive Delivery?
Progressive delivery emerged because teams wanted to ship faster in smaller increments. That meant having a higher cadence. They wanted to do that safely and, ideally, learn something in the process.
Goals Met By Progressive Delivery
Another way to look at the “why” of Progressive Delivery is to consider the top goals teams look to accomplish by implementing it.
Goal #1: Avoid Downtime
The first goal is to avoid downtime, whether that be planned downtime of a maintenance interval, or unplanned downtime, the dreaded #EpicFail in the midst of going live.
Goal #2: Limit the Blast Radius
The second goal is to get early visibility of the health of your rollout and to “limit the blast radius” when things do go wrong. Ask yourself, “Do I have a way to get an early idea of how this release to production is going, before I impact all of my users?”
Goal #3: Learn During the Process
The third goal is to learn during the process. This is what Sam Guckenheimer emphasized when he used the phrase “Progressive Experimentation” as we discussed in the last episode.
By “learn,” we don’t just mean “detect problems so we can revert” but capture and quickly make sense of observations on both technical and business dimensions so the very next iteration can be a meaningfully informed one.
Ask yourself, “Do I have a built-in (i.e. automated, repeatable, consistent) way to learn things about my users and/or my infrastructure at each stage of the Progressive Delivery process?”
Shades of Progressive Delivery
Let’s see how each of the Four Shades of Progressive Delivery accomplish some or all of the three goals we just laid out.
Blue/Green Deployment
Blue/Green Deployment really nails the first Progressive Delivery goal well, which is to avoid downtime.
The way it does that is that you have your production running on the “blue” infrastructure and then you stand up “green” which is a copy of your production infrastructure:

You take your time to install the new release on Green, do your smoke tests and make sure everything is cool. When you believe you’re ready, you do a clean cut over from Blue to Green, routing your production traffic there:
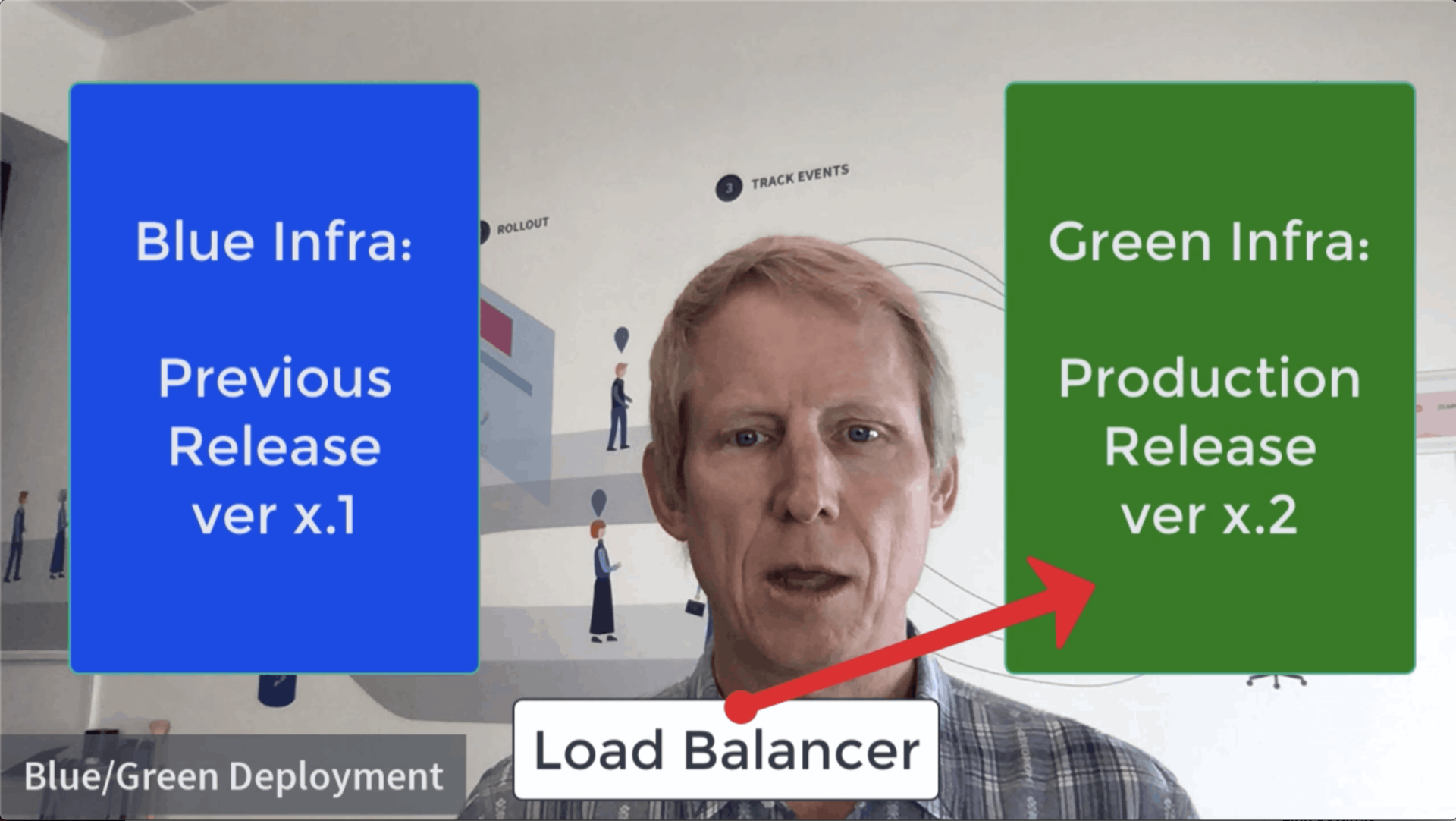
If you missed something in your testing that shows up when you go to Green, reverting is really easy: just switch back to blue.
If things go well, you stay on Green. Then you recycle the Blue environment to become the next staging area. That’s Blue/Green.
How Well Does Blue/Green Meet Our Goals?
Blue/Green Deployment is a “lighter” shade of Progressive Delivery because while you are accomplishing the goal of no maintenance interval/limiting unplanned outages, you are still doing a big bang release on two fronts which makes goals 2 & 3 hard to achieve:
- You go live for every user at the same time.
- You take the entire deployment live. If things go wrong, you roll back the entire deployment: It’s all of the new features or none.

Canary Release
The second “shade” of Progressive Delivery is the Canary Release.
In a Canary Release, you’ve got your infrastructure up. Let’s say there are 100 servers and you want to try out your new release on just two of the servers, sending 2% of your population there.

You will need some logic somewhere to figure out how to route those users and you’ll need to decide whether the user routing decision needs to be sticky (it probably does).
You route some of your traffic to these canaries and pay close attention to how those servers are doing and whether there are errors.

If anything goes wrong, you just drain the traffic from whatever is sending the traffic to those canaries and route back to production. Then you are back to the way you were at 100 percent production.

How Well Does Canary Meet Our Goals?
Canary Release is a slightly “deeper” shade of Progressive Delivery
Here you are avoiding planned downtime (as you do with Blue/Green) and you are also limiting the blast radius.
While it’s not big bang in terms of going live for every user at the same time, it’s still go/no go for everything in the deployment as one big chunk, so we still have this limitation:
- You take the entire deployment live. If things go wrong, you roll back the entire deployment. You release all of the new features or none.

Feature Flag Rollout
The third shade of Progressive Delivery is the Feature Flag Rollout.
This is a big leap in the evolution of the idea of Progressive Delivery. It’s no coincidence that the term emerged after many teams started using feature flags to roll out features gradually, essentially doing a canary release at the feature level, slowly exposing features.
With Feature Flag Rollout, you deploy the code with the new features turned off.

First, you might expose the code just to the dev team for a final smoke test on production. Next, you might dogfood, exposing the new features to your employees only (again, this is on production). If things are still going well, you start to ratchet up the rollout into your actual user population. This gives you the chance to expose new features to 5%, 10%, 20% of your users in steps as you go, and to be able to see how it’s going before ramping higher.

With feature flags, reverting your release is really quite simple: you just ratchet back the feature flag setting. If you had it out to 10 percent of your real users and you find some unexpected issues, you might go back to just dogfooding or even just back to the dev team. You are still deployed to production, but you’re not exposing the new code to your customers.

Now we’re not dealing with the whole release as one big blob!
We have individual features that we can toggle or ramp up and down. That’s really important, because it’s pretty rare that you’re only taking one thing live in a deployment.
Let’s say you take five code changes (i.e. features) live in your deployment.
Along the way, you notice that just one of them has a problem. With a Blue/Green or a Canary, the other four features have to roll back as well. The features that are OK are forced to go away and wait for another delivery vehicle.
With feature flags, you can continue to roll out the four good features even as you roll back the fifth one to fix it.
I wrote a blog post a while back about the difference between canary deployments and feature flag rollouts as release strategies.
The tl;dr is that there is a quality of life difference. If five teams are taking something live tonight and one team has a bug and the other four can’t take their stuff live, it’s a bummer. You don’t want to be that 5th team, and you want to be the four teams that have to wait. It’s great to have the fine-grained control of Feature Flag Rollouts.
How Well Do Feature Flag Rollouts Meet Our Goals?
Feature Flag Rollouts are the deepest shade of Progressive Delivery we’ve discussed so far.
We are no longer “big bang” on either the user population or deployment payload fronts. We can gradually release to expanding populations (dev team, dogfooding, percentages of users) and individually ramp up or ramp down individual features so the solid ones get out to users while the not quite ready for prime-time ones roll back to launch another day.

Feature Delivery Platform
The final model I want to talk about is the feature delivery platform, which fast-moving teams use to manage, monitor and experiment with features as they are rolling them out.

To learn more about this model, you can look into what Microsoft has done with EXP, their internal platform, as well as the in-house systems at LinkedIn, booking.com & Wal-Mart. All of these teams have built platforms for controlling rollouts and watching how they go. They have different levels of business rules around when they can go all the way to 100 percent of the users.
Feature Delivery Platforms in a Nutshell
The basic idea is that you want to be able to monitor how it’s going as the rollout is taking place. There may be times where you want to go further and experiment, watching two (or more) different user cohorts to see if their behavior changes as you intended by the release.
In some of these shops, you can’t roll out to the rest of the users until you prove that you’ve done no harm. Where the bar is even higher, you might have to prove you’ve accomplished some kind of a goal you were setting out to achieve with the release in the first place.
Wait! What? We Had to Roll Back?
Sure, it’s a bummer to have to roll back after you thought you were “done” but it’s actually great to have the detailed information about what happened and to be able to iterate on the idea in an informed way so you can try again to nail it.
Show Me The Flow
On the wall in the Split all-hands room is a graphic that brings this to life.

You’ve got users coming along the left and they’re switched by a feature flag in your code (the traffic cop). In this case, 10% of the users are going up to the new feature in the blue box, and 90% are going around.
We talked about this in our first episode of Safe at Any Speed, but I want to bring this up here as an example of a Feature Delivery Platform. Here you’re switching users to send them where you want them to go and then you’re tracking what happens and measuring the outcomes. This holistic approach (no fire drill to figure out “how are we doing?”) is what lets these teams move much faster with greater safety.
How Well Does a Feature Delivery Platform Meet Our Goals?
A Feature Delivery Platform is the deepest shade of Progressive Delivery we have seen so far.
In addition to avoiding downtime (Progressive Delivery Goal #1) and limiting the blast radius (Progressive Delivery Goal #2), Feature Delivery Platforms also build-in the learning as you go (Progressive Delivery Goal #3). Better yet, they accomplish all three of these goals at the granularity of individual features.

Final Thoughts
Better Together?
You can mix these approaches together. You might use Blue/Green to take the deployment into production, while having feature flags off for the new stuff, and then ratchet it up. Or, use a Canary Release to get the code into production (again, with the new features turned off), and then use feature flags to ramp them up.
Bleeding Edge or Table Stakes?
Whether you are using feature flags and an ad-hoc means of watching what’s happening, or have implemented a Feature Delivery Platform with built-in abilities to make sense of what’s happening (like Split), the deeper shades of Progressive Delivery are no longer only available to teams with massive internal tool squads.
Soon, moving fast, staying safe and learning as you go will be as mainstream as git and CI and established as table stakes for effective continuous delivery.
It’s a great time to be building a sustainable software delivery practice!
Jump back to the first episode of Safe at Any Speed: What’s The Difference Between Feature Flags and Other “Flags” in Software Engineering?
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.
Switch It On With Split
The Split Feature Data Platform™ gives you the confidence to move fast without breaking things. Set up feature flags and safely deploy to production, controlling who sees which features and when. Connect every flag to contextual data, so you can know if your features are making things better or worse and act without hesitation. Effortlessly conduct feature experiments like A/B tests without slowing down. Whether you’re looking to increase your releases, to decrease your MTTR, or to ignite your dev team without burning them out–Split is both a feature management platform and partnership to revolutionize the way the work gets done. Switch on a free account today, schedule a demo, or contact us for further questions.