
Here’s the video of my talk, “Experimentation for Speed, Safety & Learning in CD” delivered at QCon New York 2019. I’ve edited it down to 39 minutes, so you can easily fit this into a lunch hour or possibly a commute.
Text and screenshots follow the video below:
Transcript and Screenshots
William Gibson once wrote:

Think You Can’t Do What Amazon Does? Think Again.
We look around and we see Amazon, we see LinkedIn we see Booking.com. We see these companies that do these amazing technical feats, and we think, “Well, I don’t have the scale or I don’t have the team to build all that tooling to do the same things.”
My goal here is to spread this around: there are practices you can actually take away with you which have been around for a decade or more which you can mimic, even if you’re not one of these giants.
You are going to leave here today with three takeaways that you can use to adapt your own practices, whether it be to adapt systems you’ve built in-house (or plan to build in-house), or whether you’re going to be shopping for something to fill in the gaps.

The title of the talk today has the word experimentation in it: Experimentation for Speed, Safety, and Learning.
Continuous Delivery With Control & Observability Built-In
I want to define experimentation this way, which is that it’s continuous delivery with control and observability built-in, rather than ad-hoc.

Why Do We Do Continuous Delivery In The First Place?
Remember why we do continuous delivery? I want to get ideas out to someplace I can validate them much faster. I don’t want to wait six months between “I think we need this” and, “Is this okay, customer?” I want to go much faster. You might say, “Well that’s an agile thing… it’s agile or scrum.” It’s modern software. How do I reduce the time between idea and delivery so that I can find out more quickly whether it’s working?
A lot of the steps in this are to automate. It used to be that the build was something you did manually. We had a build manager (five companies ago) who literally would say “Oh we’re doing a build on Thursday” and everybody had to get their stuff in and that person was crazed for 48 hours while they made sure everything would come together and work. Now, you change your code, and a build server kicks in. Jenkins or something takes over and before you know it, you know whether it works or not, and with much less scramble, right?
Wait. You Haven’t Automated The Feedback?
We do continuous delivery so that we can try something and get feedback. People are focused on the try, try, try, do, do, do, but the feedback is still manual and ad-hoc.
I ask people: “So how do you find out how it went?” They say: “Well, you know: we look in the logs or we do some database queries or we have some analytics here and some analytics there.” Me: “How often do you do that? For every little change you do?” The telling reply: “Oh no! We wouldn’t do that for every little change we do! We do it for something that is obviously broken or if there’s some huge thing that we’re trying to brag about but otherwise we don’t really have time to look.” That breaks the whole idea of trying to have a feedback loop.
Continuous Delivery Defined
So what do I mean by continuous delivery? We’ll have a textbook definition and then we’ll have a more fun definition that we can maybe jump out to the bar to prove later.
Jez Humble writes a lot of great stuff and he defined it like this:
Continuous Delivery: the ability to get changes of all types — including new features, configuration changes, bug fixes and experiments — into production or at least in the hands of users somehow safely and quickly in a sustainable wayJez Humble https://continuousdelivery.com
Sustainable is the Key
So “sustainable” again, is about automation and patterns and not having to reinvent the wheel and have a drama and have a, “I’m not coming home for dinner” kind of thing going on all the time.
The other way Jez defines this is what he calls, “The Mojito Test.”
Has anyone here heard of The Mojito Test? The mojito test is pretty straightforward: Jez says that if you’re doing this right you should be able to hold a mojito in one hand and push a button to push the latest version of your code in your repository into production with the other hand and you should be able to relax and enjoy your mojito and ideally you should be able to do this at 4:30 on a Friday afternoon. It’s happy hour! Let’s have a mojito! I’m just gonna push the latest code to production it’s all fine, right? Lots of laughs and giggles… you’re like, “Yeah right!”
Some people actually are so dialed in to what they’re doing and have things so automated that they can actually approach The Mojito Test, right?
What Sort of Control and Observability in CD?
So that’s continuous delivery, but what sort of control and observability are we talking about here? That could be a lot of things, right?

This is an image of a continuous delivery pipeline.
It’s not blown up big enough here. Don’t worry about trying to read the steps, it’s just this, which is that I check in code and then maybe a test runs and if there’s a problem, maybe I’m told and I make an edit and I check it back in and that test passes, so something else happens and you know the build happens and then you go through various environments and eventually you get to production right? So that’s a continuous delivery pipeline. Actually, that’s not what we’re going to talk about. That’s “How does my pipeline run?”
Observability: do we mean observability of the pipeline itself?
This is a screenshot of something called Hygeia which was built at Capital One. They’ve given it away as open source. Those steps in there (again I didn’t blow up this picture), but they’re just basically how much time does your code spend in commit, and build, and this kind of test, and that kind of test. You know the performance test one, of course, is the biggest because it takes days instead of minutes. Then, the very last box is how long has your code been in production. How many days has it been since we had a push to production? So this would be trying to keep track of how everything’s moving, but nope, that’s actually not what we’re talking about.
What we’re talking about is actually something more fundamental: if we’re not talking about the pipeline, what are we talking about?

Well, the payload. Why are we doing this in the first place? What is it that the user is actually going to see or experience? Is the customer is going to smile or not smile, right?

I wrote this, which is, “Whether you call it code, configuration or change, it’s in the delivery that we show up to others.” When you deliver you show up for others. People live in fear of doing a delivery which breaks things, right?
You know you really don’t want to push some software into production and have everything go down. We want to deliver and have people be delighted, or at least not notice when something’s wrong.
So that’s what we’re gonna talk about.
Control of Exposure

Control in this sense is really control of exposure. Who is going to get the code when? How do I control who sees it and how do I make that control something that’s selective?
You’ll hear terms like blast radius. Has anyone heard about limiting the blast radius? Some nods out there at limiting the blast radius, so you know it’s kind of a scary war-like thing… when a bomb blasts – there’s a blast radius.
Microsoft actually has this notion of concentric circles and if you ever use the Microsoft products, in the updates you can configure what kind of a user you are. “Oh, I’m an early preview user or I’m a hey you know make sure it’s all stable user.” There are steps you can put in there. To go from the first ring (they call them “rings”) to go from the first ring to the outermost ring might take three weeks or more at Microsoft because they’re going through the motions and making sure everything is cool, right? So that’s blast radius, right?
Another way to look at it is “the propagation of goodness.” If you’re making a change let’s say some people are saying, “I need this! I need this! I need this!” Who’s gonna get that change, right? How do I control who gets the thing I just did? Maybe I’m sending it to my friendly customers. Maybe I’m sending it to somebody who is contractually obligated, you know, we have to get it to them or whatever.
The last way, which I really like, is to define this as “the surface area for learning.” Remember, the point we’re making here is that we’re trying to figure out how do we build stuff and get feedback quickly without drama, right? So what’s the surface area for learning? How do I control where we’re learning from? Just a little area is probably not a good thing if you need to make sure that this meets the needs of a lot of people, right? But, if you’re trying to figure out whether something is really brutal on the CPU you probably don’t want to ramp it up to all your users right away.
Decoupling Deployment From Release
So here are some key things (and we’ll go back to the takeaways), but in terms of this how do I decouple deployment from release? How do I make it so the deploy is not the same thing as release? A lot of people think that when you deploy to production, well “You’ve deployed to production! It’s there! Oh my god! Oh the users, whoa!” because we think that they’re one and the same a lot of the time. But, If you can decouple deploying from release, the deployment is really just infrastructure. It’s just moving bits around. Release is when you choose to expose things to users.
For some of you, this is a paradigm shift thing: what if I push the code all the way into my data center where millions of dollars are transacting, but no one saw it and it didn’t execute. Is it really there or not? Well, it’s there but you haven’t released it yet.
Decoupling Revert from Rollback
The converse is true and actually more importantly true: how do I decouple reverting from rollback? If there’s a problem, how do I actually just say “undo” not, “Oh wow! We’ve got to restore! We’ve got to kill those servers!” or “I’ve got to bring back up the other environment!” How do I not have it be drama? How… I’d like a button… to push a button and I say oops and now everything’s back to where it was, right?
You’ll hear about blue-green environments which is the idea of having parallel environments running and you bring up a duplicate of your entire infrastructure and you don’t put anybody through the new version until you think it’s ready and you leave the old one there in case something goes wrong and you start filing people through here and if it gets ugly, you bring this down. Well, that’s a lot of duplication and cost, right? What we’re gonna talk about here is actually much fewer moving parts and much cheaper.
Feature Flags: Where We Get Control
Feature flags: Show of hands… Who has heard of feature flags before today? Okay a lot of you, which is great. Feature flags… sometimes I’ll mention this and some people say, “Yeah! Yes… so when we compile the software, we have a flag which determines what the output of the compile is, right?” That’s not a feature flag. That’s a build time flag that controls this fixed object you end up with. Or, they will say, “Yeah. I have feature flags. When I launch the server, I have a command line argument that turns this on and that server is an experimental mode or it’s doing the different thing, right?” No, that’s a server configuration thing. That’s not really a feature flag. The last example you’ll hear is, “Well, I’ve got this configuration file. We read it every 90 seconds, so all I have to do is push the new version of that configuration file and the server will change what it’s doing.” Again, that’s at a server level, right? That whole server is doing that.
What we’re talking about is user by user switching what happens dynamically to users as they pass through the code. So you’ve got a code path that’s maybe new and you decide, “Do I send people down the new code path or not?” You want to be able to control this all the way down to the level of a single user, but also be able to use populations as aggregations, like all of my beta people or all my internal testers whatever, right?
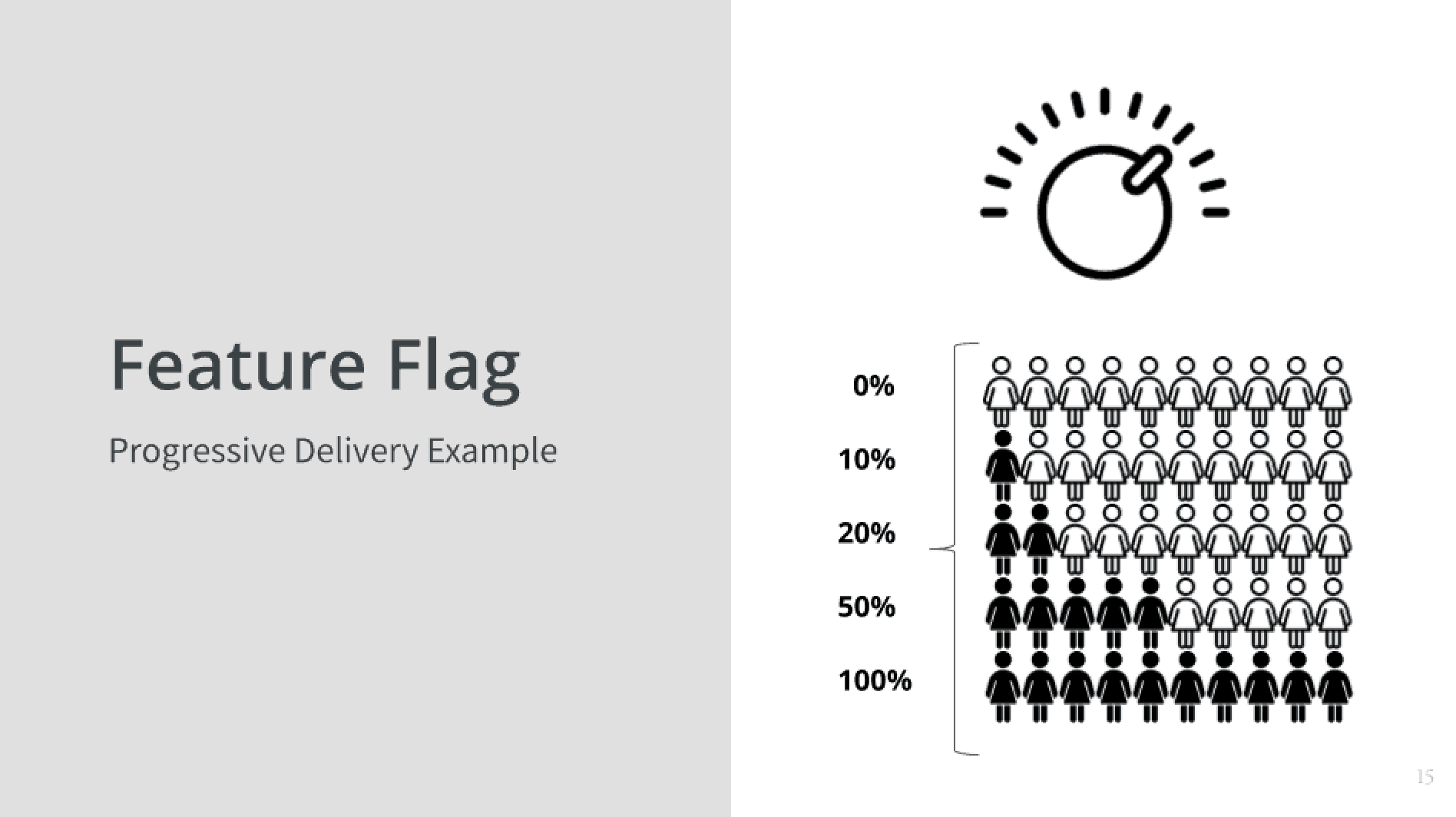
A Rollout to 0% of Your Users?
So in this diagram on the right, you see first a knob, turning it up and down, and then you see that the first line is 0%. If I’m doing a rollout, why would I roll out to 0%? The short answer is because it’s not ready yet. If anyone’s heard of trunk based development or monorepo, the notion of having only one version in source not lots of feature branches, but actually having one branch that everything lives on in order to pull that off and actually not have things break in production or people see half-baked features, you need the ability to push a feature all the way to production but have it dark, have it off or latent. Have it not there, right? So that’s the zero percent.
Then you see the 10% and 20% and 50%? That’s the notion of ramping it up a little bit of time and watching it as it goes and deciding whether it’s okay.
Online Controlled Experiments
There’s another use case though, which is you’re deliberately trying to run an experiment. I mean, everything we do is kind of an experiment when you think about it. Like, “Okay, we’re gonna deploy… did it go right?” But, when in this case, you might be asking, “Will presenting five options to the user instead of three options be better for us or not?” Or, it might be, “I need to know whether this new search algorithm that people are so excited about really is going to work. It’s not going to tank the server. Are people going to like the results?” So, you might have a legacy search algorithm and the new ones you’re trying and you’re going to route traffic and put 80% of the people through the legacy and 10% and 10% through the two new ones to see what happens, that’s an experimentation example.
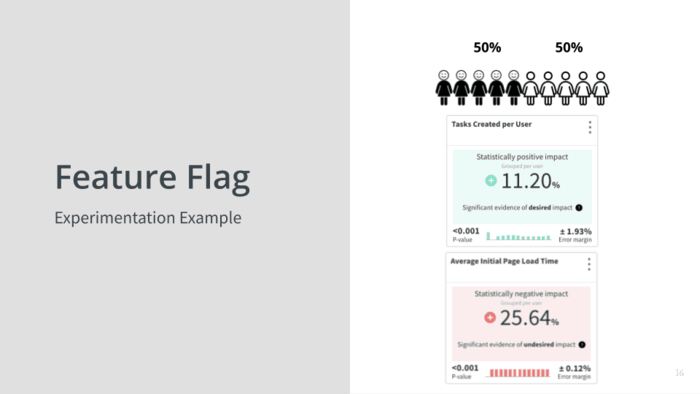
In this case we’re splitting some population 50/50, but that doesn’t have to be all of your users. It could be, you know, within my beta testers I’m gonna give half of them this or within my free users I’m gonna give half of them this or within my people that don’t have contracts that say if I hurt them I owe them millions of dollars, whatever.
You’re going to split the population, and the first card there you see says tasks created per user and it says there was a statistic… it’s a statistically positive impact of eleven percent. It’s green! We’ve accomplished something! But, what if while we were doing that we actually tanked performance like the page response time went down by 25%?
Now, we’re only doing this to a small number of users and so far they’re not like fleeing in droves, but if we know this, we might say you know what even though this is working to get more tasks we might want to pause here and actually fix the performance issue before we ramp it up, right?
Again, a lot of these concepts are not like deep theory; we don’t have to actually call this a PhD course in technology to understand that it makes sense, right? The problem is that those boxes there? Most people don’t have those boxes. Without those boxes, you need to have a data analyst dig around and mine for tidbits or an Operations person look through the logs or look in Datadog or whatever, and it’s all very ad-hoc. The first thing we said at the beginning was, “How do we do this and not have it be ad-hoc?” How do we make this just automatic? We will revisit that after we have a peek at what a feature flag looks like in code.
Code Sample

I’ve given a really simple kind of pseudocode example here: treatment = flags.getTreatment (related-posts). This is an example of an on/off example. If the treatment is “on” (if that function call to get treatment comes back with “on”), then I’m going to show related posts, and if it comes back with anything else, I’m just gonna skip this. I’m not going to show the related posts. So, that’s a super simple on/off example.
Multivariate: this is the one I kind of gave about the search algorithm earlier. So, get treatment for search-algorithm: if the treatment is v1 do that, v2 do that, else use the legacy one.
What you don’t see here is that is that the function call carries with it the user and the context (however much context you want to send), so who is this and what do I know about them that I want to use to make my decision. It could be a level of customer. It could be how long have been on the system. Anything you know about your user.
So that’s what a feature flag looks like in code.
What Do I Mean By Observability?
Let’s just do a quick kind of switch to what I mean by observability. So observability is kind of a term on the rise lately. Some people say, “Well, that means writing really meaningful messages to the log.” Some people say, “Well I mean is having a really cool tool that can do this stuff in near real time without a delay.”

Observability Part One: Who Have We Released to So Far?
What I’m saying is for observability of exposure is that I want to know, “Who have we released this to so far?” We had an intention, which we configured to say, “I’m going to my East Coast users who are beta testers and I think I’m gonna have about a thousand people if I do that or a hundred people or whatever.” I want to be able to see who actually has seen this and who hasn’t, like who came through the switch and got one thing or the other. So that’s observability of who’s seen it.
Observability Part Two: How Is It Going for Them (and Us)?
Then, this is the really important part and this is the part that almost nobody has. Some of the most sophisticated companies I talk to, I’ll ask, “So, how do you know how it’s going?” The answer: “We dig. We dig manually.”
So how is it going for them and for us? How are the customers doing? Are they doing more of what you wanted? Are they leaving? Are they unsubscribing? Are they buying more stuff? Are they bouncing? How’s it going for us? Are we getting more errors? Are we using more capacity? Are we actually burning through more server capacity with something that wasn’t supposed to? How’s it going for them and for us. That’s what I mean by observability.
These are on the surface really simple questions, which is “Who’s got it?” and “How’s it going?” The devil is in the details! How do I figure out who’s got it if I’m just routing traffic through different servers or whatever.
Role Models Who Do This Well

So here’s the meat of the talk: “Who already does this well and is generous enough to share how?” This is the part where I’m kind of saving you a lot of research. Everything I’m going to show you is actually available and there’s links in my presentation which I’ll share later if you want to go read the details yourself.
LinkedIn XLNT

The first one is LinkedIn and they have something called XLNT. We will start with their humble beginnings. They knew that they needed the ability to try things out and not break everything for everybody all at once. I think a lot of us have something along those lines. They built a targeting engine that could split traffic between existing and new code.

I was watching a video where they explained this process. Impact analysis was done by hand and took about two weeks. If you could beg a favor from a data scientist, you would get an answer in about two weeks about whether your thing really did the thing you wanted it to do. As a result, pretty much nobody did that because that’s a big favor to ask and it’s a long, long time to wait.
So, essentially they just had feature flags… they had the ability to make decisions, but they didn’t have the automated feedback.
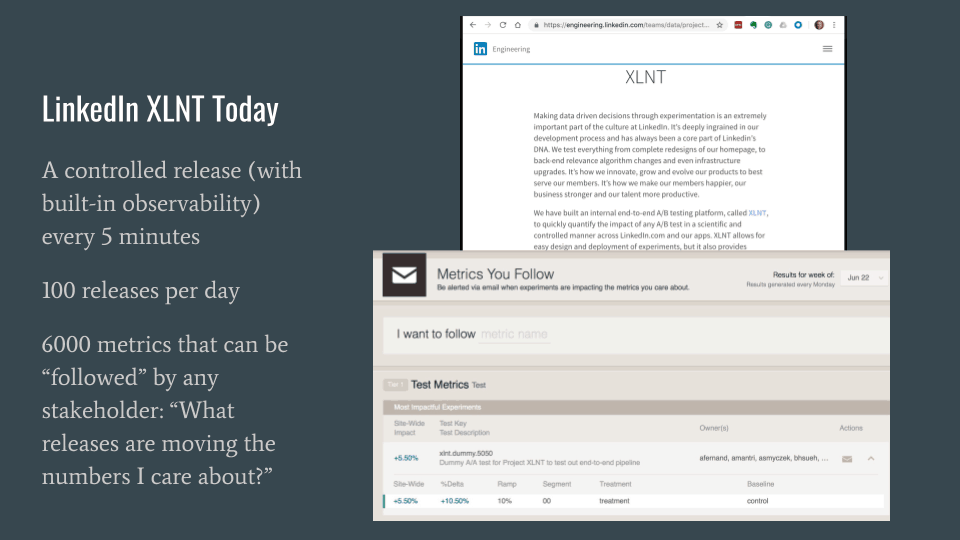
Fast forward to today and they do a controlled release with automatic built-in observability every five minutes… about a hundred of those a day, where they don’t have to do any ad-hoc thing. They just follow the patterns they’ve built, use the internal platform they constructed, and they do this all day long.
At the bottom part of the screen where it says, “Metrics You Follow,” that’s a fairly decent looking UI. That’s an internal system. This lets non-technical users or technical users search for metrics they care about and basically subscribe to who’s messing with those metrics. So, if I really care about newsletter subscriptions and I’ve got 40 development teams or five whatever, or three, and I want to know anytime somebody launches an experiment which is moving the needle up or down for subscriptions, I subscribe to this thing, Metrics You Follow, and I say I care about subscriptions. I might get an email or a slack or something that says, “Hey! Tony’s running an experiment and for the people going through his experiment, 30% fewer of them subscribe.” Or, “Wow! He’s doubling the subscription rate!” You get this proactively. You get to be notified so this is a very advanced.
They’re way ahead. Talk about the future! They’ve been doing this over and over again and they don’t want to have DBAs and people taking requests to set an alert for me when something moves a metric. They’d want to make this easy and automated.
Guardrail Metrics: Don’t Drive Us Off a Cliff
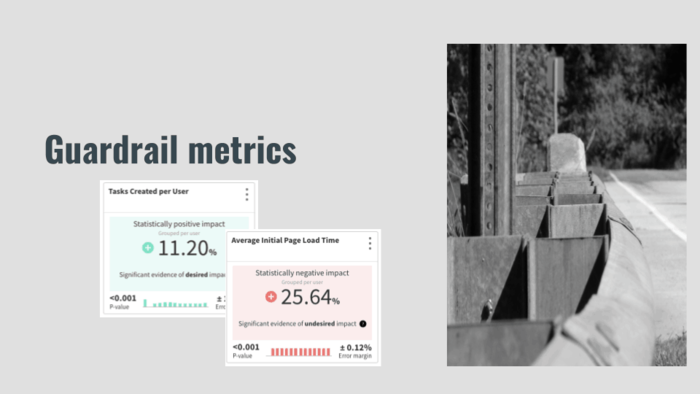
LinkedIn is where I learned the word “guardrail” as in guardrail metrics. That’s a picture of a guardrail on a road. If you get a little crazy and the car starts to go off the road, you’ll bang into it. Before you fall off the cliff, you’ll go “ka-thump” and you’ll stop.
The idea behind a guardrail metric… we saw these earlier, which is you know if your team is working on something what are they going to try to optimize? They’re optimizing the thing they’re working on. Their job to focus on making this one thing better. It’s generally not thought to be their job to, “Oh, by the way, also watch all other things.” If you if you gave that as an assignment to a developer, that’s crazy, right? So a guardrail metric is the idea of deciding is an organization, “What things do we always want to keep track of without anybody having to work to do it?” For instance, you have metrics in your organization: could be response time, could be failure rate, could be business metrics like unsubscribes, whatever purchases per user per hour, whatever there’s a metric.
So guardrail metrics are those metrics which that local team is probably not focused on but which if they knew they were hurting they would probably say, “Oh! Oops! I better not break that.” Think about it what would make the directors and the VPs and the C-suite be unhappy. In that example I gave, you know the load times going up 25%, you probably want to take a second look at your thing before you roll it out your whole population.
Lessons Learned About Building an Experimentation Platform at LinkedIn
So, that was the journey of LinkedIn. Here is Ya Xu, she is the head of data science there. She started out as an individual contributor and she rose to run this whole team. I believe there are over 100 maybe 200 people on her team now. She boiled it down to some lessons you can take away.

Build for Scale
First of all, build for scale. They used to coordinate these experiments over email dialogues. And, by the way, when they started they used your user ID last three digits or two digits. When you became a LinkedIn remember you got a unique number that they had internally. It just so happened that if your number ended between this and that range you got a lot of experiments and if it didn’t you never got an experiment. Then they would argue over which range each team could use for their experiment: “I want 37 through 45,” or whatever (I don’t know the numbers). They basically had this because they don’t want to collide with each other. They realized that’s not going to work when you’re goal is to be able to do a thousand of these at the same time. You can’t do that if you’re debating over email.
Make it Trustworthy
The other thing was that they had, in their early days, they had some issues. They would run experiments and people would come into the experiment and say, “Awesome news! 50% change in the good!” So you’re a hero and then they would go home and they’re tell their spouse, “We are rock stars!” only to come in the next day to show their boss: “Check it out! Let’s look at the results!” and they bring up the screen and it says, “Bad news, you’re 50% down.” They’re like, “But. But. Wait!” and they had these kind of flapping and they had all sorts of other issues where people didn’t trust the data.
If you had data like that, you would say, “Yeah I’m not gonna use that tool. I don’t think that’s gonna help me prove my case.” So they realized they had to make it trustworthy and had to make both the targeting of who got the treatments and the analysis to be defendable. It had to be repeatable & defendable: people had to believe it. We’ll see how that has an impact on your ability to kind of roll this out throughout your team.
Design for Diverse Teams: Keep Teams Autonomous by Avoiding Constraints
Finally, design for diverse teams, not just data scientists. so who here has ever had some really awesome thing in your shop that only one person knew how to use? Typically there’s a wizard. I was selling shift-left performance testing and we went to a bank and they said, “Oh no. We’re getting out of the choke point of a centralized testing thing. We’re moving to this open-source stuff, much like what you’re building, but we’re building it ourself. We don’t really have a reporting front end, but Bob over here, he can actually get the results to any test and analyze it and share it with teams.” I said, “Yeah. You realize Bob’s gonna be a little bit of a bottleneck, right?” So if there’s somebody… there’s only one person or a small group of people that know how to do a thing then inherently it’s gonna be a bottleneck.
One of the key principles of agile and DevOps is, “How do I eliminate constraints? How do I make it so there aren’t handoffs? They aren’t waiting. There’s not stuff queueing in places. How do I make the team autonomous so they can actually get their work done without having to wait on somebody else? So, design it for diverse teams not just data scientists so that anybody who wants to use this can get their hands on it and roll.
Use a Centralized Platform for Consistency and Give Local Team Control for Autonomy
The last thing I’ll share from LinkedIn is this thing they came up with. I know we come from a lot of different environments, but one of the models people are moving towards is this goal of local autonomy of teams. The more a team is autonomous, they’ll like their job better, and frankly, they’ll spend less time waiting for other people. So how do i balance the idea of giving people autonomy with the need for some kind of consistency so the data will stick? If every team has a different way of deploying and measuring then they’re not going to believe each other or they may run into issues.

What they came up with was that you really need to have a single way to do this with well published guidelines that are easily read in a few minutes and when you do then your ability to have the observations be trusted and understood across the organization goes up exponentially instead of a he says, she says / that team vs. this team thing.
Beware of HIPPOs Making Technical Decisions
If you can get people who are less technical (who would normally weigh in and veto things without understanding them) to actually believe the system, then you end up with letting the data do the talking not somebody’s opinion. Show of hands please: who has heard of “HIPPO: highest paid person’s opinion?” It’s nice to have clarity in a situation where there’s chaos, but you don’t necessarily want somebody who has the most money on their paycheck being the one who says which technical decision you should go with. It doesn’t doesn’t always go well for everybody.
Booking.com

Next, we’ll talk about booking.com. Who here has used booking.com, and knows it? (they own things that aren’t called booking.com too). At least half of you raised your hands. Booking.com, headquartered in Amsterdam, is very tech-forward. They do a lot of cool stuff and they’re very public about it which is awesome.

Wrap It and Watch to See What Happens
They treat everything they do as an experiment. They don’t decide to run an experiment and then do something different. Every time they push any kind of change to their infrastructure, to their code their app, anything, they wrap it in an experiment. We’ll see how that worked out for them.
They have a thousand of these running on any given day. That’s not starting a thousand, but there’s always about a thousand of these running at any one given time.
They see observability through two sets of lenses, which is really kind of a brilliant expansion of what the LinkedIn guys were talking about.
- First of all it’s a safety net. So they want to be able to watch so they can quickly detect if something is going wrong.
- The second one is to validate ideas which you might think of it’s more like traditional experiments, A/B testing, whatever like, “I’ve got this hypothesis. I want to validate it.”
They do both of these things.
This guy Lukas Vermeer is the head of experimentation there and he does a lot of awesome public work. He does talks. He does videos. He writes papers.

Another Way to Say Decouple Deployment From Release: “Asynchronous Feature Release”
Lukas talks about booking.com’s experimentation platform this way: the first value is the asynchronous feature release. “How do I decouple deployment from release?”

Far and away the greatest value they get from their experimentation platform is that no user is impacted at all by pushing a change until they decide to start ramping up. So, no impact on user experience.

They can deploy more frequently with less risk to the business and users. If you think you’re gonna hurt users with things you try, you’re gonna be more reluctant to try things and you’ll be slower, you know, putting more time into double double checking everything. The big win is agility. They figured that they do new things much more often because it’s not so scary.
Experimentation as a Safety Net
Next thing: experimentation as a safety net. This is where it’s really interesting for me.

Every new feature is wrapped and they can monitor and stop any change. Remember, they believe in this local autonomy thing which is if the team has autonomy, if you’ve made a change, who’s gonna know best what’s supposed to happen? Well, the team that built it should know what should the expected behavior be, not some operations person or QA person that’s in another building or whatever right. If there is an Operations or QA person, they had better be on the same small team, because those people you understand what are we doing this week why did we push this release.
They believe in having the team be the one that watches it and enables and disables it regardless of who ends up deploying it or who had anything to do with the infrastructure part.
The Circuit Breaker
Each of these companies has a thing where they’ve done this over and over again and they’ve gotten even cooler about what they do. The circuit breaker at Booking is this.

Circuit breakers are active for just the first three minutes of a release. What it does: it watches for things that are glaringly wrong, and when it sees some severe degradation, they automatically abort it.
You might say, “But wait a minute! The local team is supposed to make this decision, right?” In this case, no. You know that if half the people going through this flow you just started to expose people to get an error, that you can turn it off for now and figure it out later. That is what they do. This is a divergence from their normal culture, but it’s a no-brainer if users are being impacted. What’s really, really crazy, and I don’t promise you could pull this off in your own environment, is that the time between starting to expose users, noticing something’s going wrong, shutting it off again (time between those data points) is a grand total of one second.
So, their mean time to detect (MTTD) and mean time to resolve (MTTR) using the circuit breaker, is inside of a second. When user has a bad page and hits refresh, it’s gone! I don’t really know how they pull it off, but that’s pretty amazing! The basic idea though, is that if you could fix something within five minutes and not have more than a handful of people in fact affected you would probably be very happy. It doesn’t have to be inside of a second but you know, high bar.
Experimentation to Validate Ideas
The last one is that they use experimentation to validate ideas.
“Given what we’ve seen, we believe that if we change this, that will happen. I just gave you the highly complex formula which is:
- Based on what we already know,
- We believe if we do this,
- That will happen.
Now you know what you’re gonna do and you know what to watch for: We’re trying to make this move or something happen, right?

They like to measure the impact changes have and every change always has a clear objective, so they know what they’re trying to accomplish. They actually write it down and that lets them validate what they’re doing: either they achieved it or they didn’t achieve it, right?
Build-Measure-Learn Feedback Loop

Lean Startup is a book about how to run like a lean startup, no matter what size you are. Instead of making complex plans that are based on a lot of assumptions, you can make constant adjustments with a steering wheel called the build-measure-learn feedback loop. This is, how do I do things fast and learn.
Stop Wasting Time (Fail/Succeed Faster)
I think the way they put this is actually more interesting. This is a quality-of-life thing by the way if you read between the lines:

The quicker we manage to validate new ideas the less time is wasted on things that don’t work and the more time is left to work on things that make a difference this way experiments help us decide what we should ask test and build next.
When you do this, you spend less time on six-month projects that get shelved!
Lukas Vermeer’s Tale of Humility
So I love this story by Lukas Vermeer. What’s hip in the DevOps space is people telling stories of how they failed. They don’t always pound their chest and say we’re awesome.
So Lukas was hired to be a very smart data scientist and they had this page that if you searched for (you had a search query on Google), you would end up on this landing page that would show you hotels in Asia.
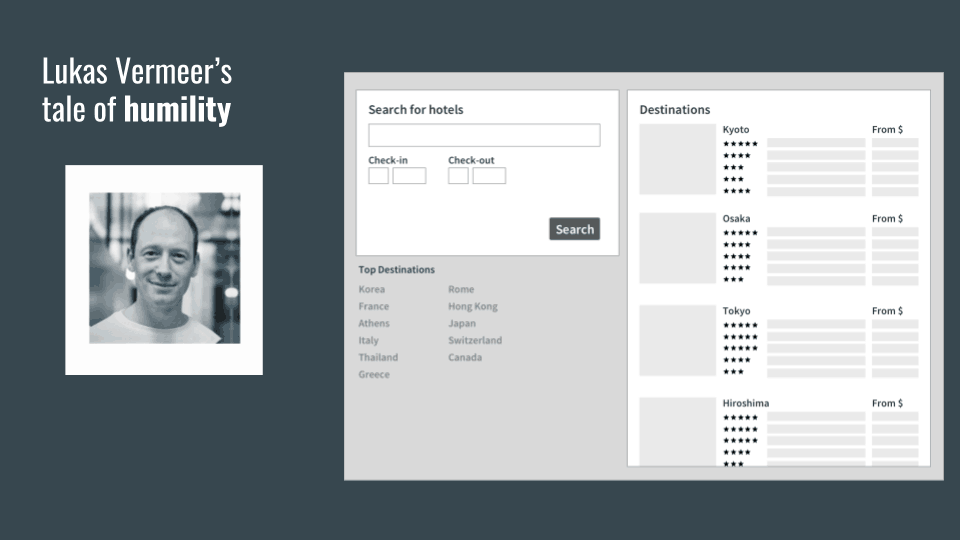
It had this list: for each of the cities it would have five hotels, and he said, “Well, I’m going to optimize this page. Those five hotels we are selecting, we need to find the smartest way to select those five hotels so that people will book more trips.” So he spent six months literally changing the order of the hotels and figuring out, “Do I do the ones people most people booked or the ones that have the highest ratings?” He tried all sorts of things and nothing changed. It had no effect on the conversion rate at all: zero, zip.
He got really frustrated and said you know I’m gonna move on to something else. Somebody at work said, “Hey! You know, before you do that let’s just do a quick HTML hack and hide the list of hotels.” They actually dug into it a little more and thought, “You know what, people aren’t really clicking on the hotels. They’re just not clicking on the hotels, so let’s just turn them off and see if anything happens.”
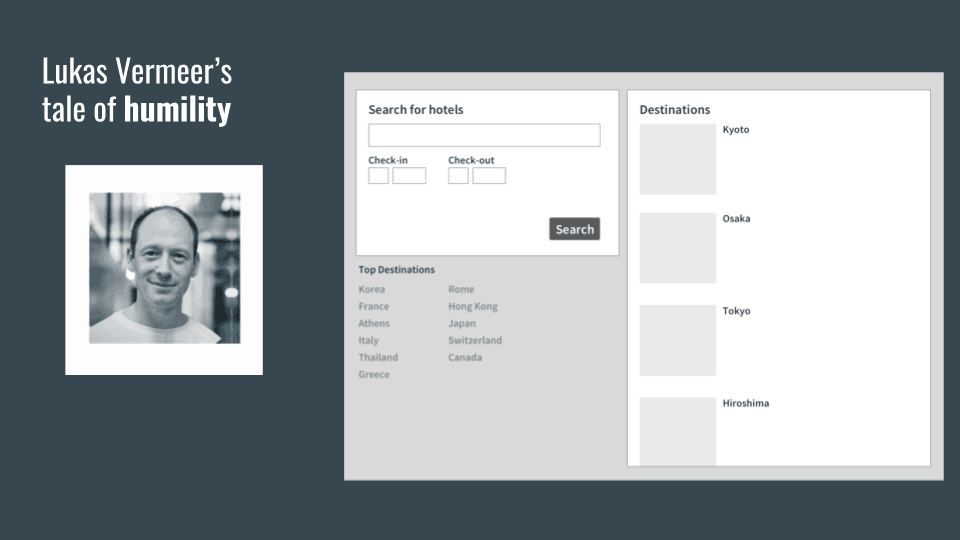
So they turned off the individual lists of the hotels, and the impact was… nothing. Another experiment, the impact was: nothing. Is that a failure? Is that a learning? I don’t know, but nothing, right?
Even A Red Diff is an Experiment
He said, “Okay. I am totally dejected. I’m out of here.” and the developer said, “Hey! Whoa! All that smart data science stuff you put into the back end there? Let’s pull that out before we move on. If we’re going to shut off that list, let’s actually not just do an HTML hack. Let’s make sure we don’t do all that calculation.” So they wrap that in an experiment and when they did they found the conversions went up.
When they just did the back end change of the code, which had no impact on the page view. But why was that? Anyone want to guess why conversions went up when they changed the backend code? Quicker! Yes, right answer! It was faster. It was just a little bit faster, so more people liked that. They were all going to that search box on the top left anyway and when it came up faster more people used the service and booked.
So, kind of a messy story, but the fact that they wrap everything in an experiment meant that they got to the good thing without it just being kind of crazy chaos.
Facebook Gatekeeper
This is the last one I’m going to cover, and then we’ll get into the takeaways and wrap things up. Facebook gatekeeper.

I don’t know if anybody’s heard of gatekeeper. We’ve all heard of Facebook. Some of you might like Facebook some of you might not like Facebook. It was where I did all my family photos for a very long time. Now I have a private way to do that and I’m happier with that.
Coping With Massive Scale Early On
Facebook had to cope with scale from very, very early on, and the way they chose to deal with it wasn’t to have lots of rules and lots of structure and lots of change committees and that kind of stuff. It was the reverse of that, which is they sort of promoted chaos but found a way to get through it.
Complexity as a Four-Headed Monster
There’s an article that Kent Beck wrote called Taming Complexity With Reversibility. you’ll notice there’s a four-headed monster.

Taming Complexity with Reversibility
KENT BECK· JULY 27, 2015
https://www.facebook.com/notes/1000330413333156/
Facebook looked at complexity and saw that there were four heads to the monster: there was the complexity of states… knowing what state a multi-part system is in is very hard. If you have already gone through the journey of micro-services, knowing the state of everything all the time is really, really tough.
Interdependencies: understanding all the interdependencies of a bazillion different parts is actually really, really hard.
Uncertainty: the world’s an uncertain place. Things will happen! So, understanding what’s going to happen and how to cope with it, that’s actually really hard.
The One Beast To Tame: Irreversibility
Then they stumbled on this: they said, “Irreversibility: let’s let’s look at that.” A less fancy way to say irreversibility is how do I get an undo button? How do I make, if something bad happens, how do I make it that I can reverse it? Just make it un-bad. So, that’s what they focused on.

Dogfooding (Internal Usage)
The way they did it was they would do dogfooding (aka “Internal usage”). Actually, Facebook uses their own product a lot internally and so instead of coordinating the teams, they actually just let all the teams do what they do and everybody pushes to internal users. People, if their own thing breaks, they say, “Hey! Who did what?” and it stops it from progressing.
Staged Rollout
If after an hour, nobody speaks up and says, “You broke something,” then it starts to propagate and they then deploy out to – I think it’s 2% of the population. But, you are Facebook right? So that’s millions of people. So, they deploy out to a larger population: that’s a staged rollout (a little bit of time) and they go bigger and bigger and bigger.
Dynamic Configuration
They do this by having a dynamic configuration. They don’t do this by bringing up servers and shutting down servers, they do this by their ability to dynamically control what the system is doing. That was the pattern we were talking about earlier, right? What I love here is you know, “…we can dial up features up and down in tiny increments…one tenth of a percent” to figure out the weird inter-dependencies of complex stuff. So, they have the ability to have a lot of control over this.
Correlation
The last thing is correlation: This is really the key thing right? This is the part that shouldn’t be ad-hoc: “Our correlation tools let us easily see the unexpected consequences of features so we know to turn them off even when those consequences aren’t obvious.” So, they have the ability to watch and see what’s happening.
Those are the real-life stories that I wanted to share. If you ask for a copy of the deck, I’ll you get the URLs.
Takeways
Let’s quickly do the takeaways.

Decouple Deployment From Release
The first takeaway is to decouple deployment from release:

Figure out a way to make deployment not equal to release. When you do this,
- deployment is just infrastructure (just moving bits around).
- Release is exposing bits to users.
Let’s look at a data flow of how you might do that:
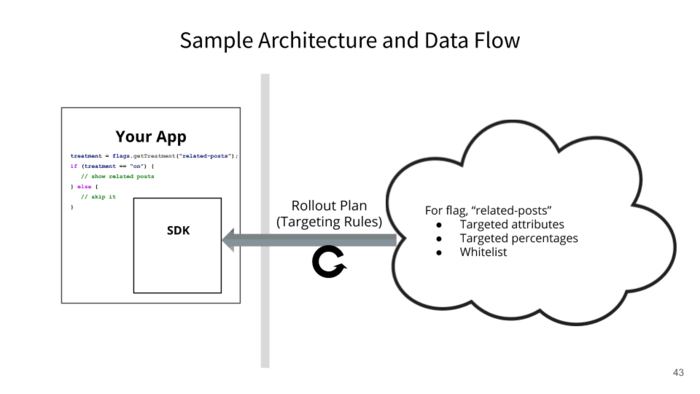
- There is your app.
- There is something outside your app that’s controlling what your app does.
- You’ve got an SDK that is part of this sort of feature flagging system right and anytime you want to run your code you ask, “Hey! What version should I give?” This is the related post thing again.
- You have a rollout plan. It’s controlled externally. This is really important: It’s not by pushing a new configuration file. It’s not about changing your code. It’s about, how do you externalize the control somehow and push those rules into the app whenever you want without having to redeploy the app?
- When you do this, keep it fresh, right? Then, you have the ability to have this control.
A question I get is, “Where should you implement progressive delivery controls the front end of the back end?”

People say, “Well, do you do this in the browser do you do this in the back?” Where do you do this? Basically, you want to favor as far back as possible so that the user is not involved.
There’s a fun little story about a woman who figured out that Facebook was using feature flags, and turned on a feature that was for dating before they had announced it, and took a screenshot.
She literally went into the browser tools and just flipped the value of something and in her browser, there was the dating thing in Facebook. She put it out there on Twitter, right? They were not too happy about this, but that’s because they were using front-end flags… they were switching at the front end. There are reasons why you might sometimes want to do the front-end, but the closer to the back the more you can use high-powered infrastructure and not involve latencies to the user and stuff.
Build-In Observability
The second takeaway is, Build in observability:

- Know what’s rolling out and who’s getting what and why.
- Align your metrics to the control plane: If you’re sending some people this way and some people that way, don’t use global metrics to watch. You want something that’s watching the same way. You’re looking through the same lens as the different populations.
- Make it easy to watch guardrail metrics without work. Don’t say, “We should all keep track of all these things.” No, make it a no-brainer so people actually just get this thing that tells you whether there’s a response time issue or when you’re causing problems.
So how you might do that:
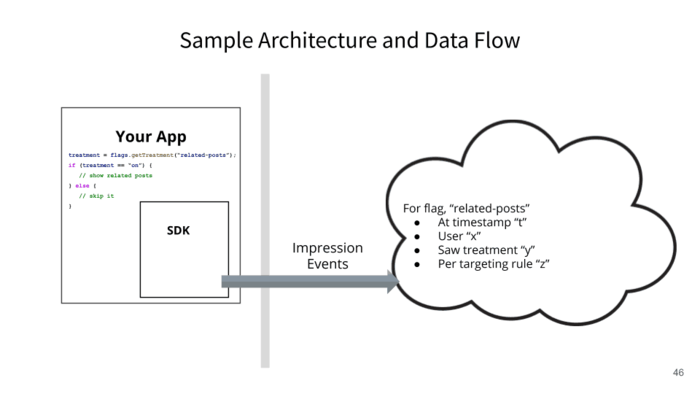
- Your app goes to use a feature flag.
- You send out a note that says, “Hey, Bob came through. He got this treatment for that reason at this time and for this rule.”
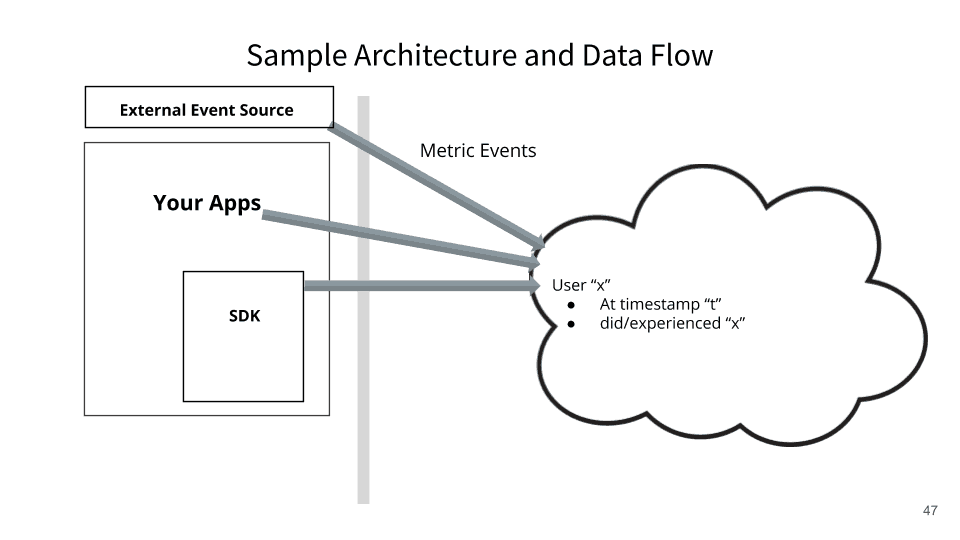
Then, you ingest events from wherever you can get them, that basically say, “Hey! By the way: Bob came by he was kind of angry. He canceled his account.” Or, “Bob bought more things or Bob had a really slow page response time.”
So, how do I ingest things with that same key, “Bob,” and know how it went? This sounds kind of complex, but there’s only two pieces of data you really need:
- One is a unique ID that was used for the decision, “Bob” or more probably a GUID or something.
- Then, when did it happen?
As long as you know those two things, you can actually correlate back to was it related to this experiment.
Going Beyond MVP Yields Significant Benefits
The third takeaway is going beyond MVP yields significant benefits.
A lot of people say, “Well, we have a system in-house that does some of this already.” If you look at the stories from these other companies, they evolved and evolved and evolved to the point where they have a really amazing thing that works great for them.

Thing is, most people I talk to at shows like this will say, “I have no way to analyze automatically and so there I am I’m doing it by hand.” So,
- Build it for scale
- Make it stick.
- Design for diverse audiences: one source of truth
Now You Know. Run With it.
I just want to leave you with one last thought, which is, “Whatever you are, try to be a good one.” this is a quote from William Makepeace Thackeray. If you’re gonna do something, just do the thing. Do it well.

I hope that the ideas I’ve shared will help you change how you do what you do. Those of you who want to go build something that does this, I hope my talk helps you go build something that does it. Those of you that want to look for a commercial solution, I hope you’ll come by and talk to the folks at Split. If you just want to brainstorm with us about how this stuff works and have a beer that’s cool too. I hope this has been useful. We have got to wrap! Thank you very much!
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.
Switch It On With Split
The Split Feature Data Platform™ gives you the confidence to move fast without breaking things. Set up feature flags and safely deploy to production, controlling who sees which features and when. Connect every flag to contextual data, so you can know if your features are making things better or worse and act without hesitation. Effortlessly conduct feature experiments like A/B tests without slowing down. Whether you’re looking to increase your releases, to decrease your MTTR, or to ignite your dev team without burning them out–Split is both a feature management platform and partnership to revolutionize the way the work gets done. Switch on a free account today, schedule a demo, or contact us for further questions.