
Over the past few months we’ve been out in the field, chatting with development and operations teams from more than 100 different organizations around the U.S. We wanted to know how they get software to market. How often do they release new features to their users? How often do they run into problems in the release process? What does great look like for continuous delivery?
We found that organizations are releasing faster than ever (nearly 20% release features daily), yet they commonly run into issues (82% commonly uncover bugs in production), and it can take a long time to get user experience back to normal (38% have a mean time to resolution or “MTTR” of greater than 1 day). Read on to see how organizations are faring when it comes to delivering features faster, safer, and smarter. We wrap up this piece with some tips on how some of these teams are implementing best practices.
Software development teams are moving faster than ever
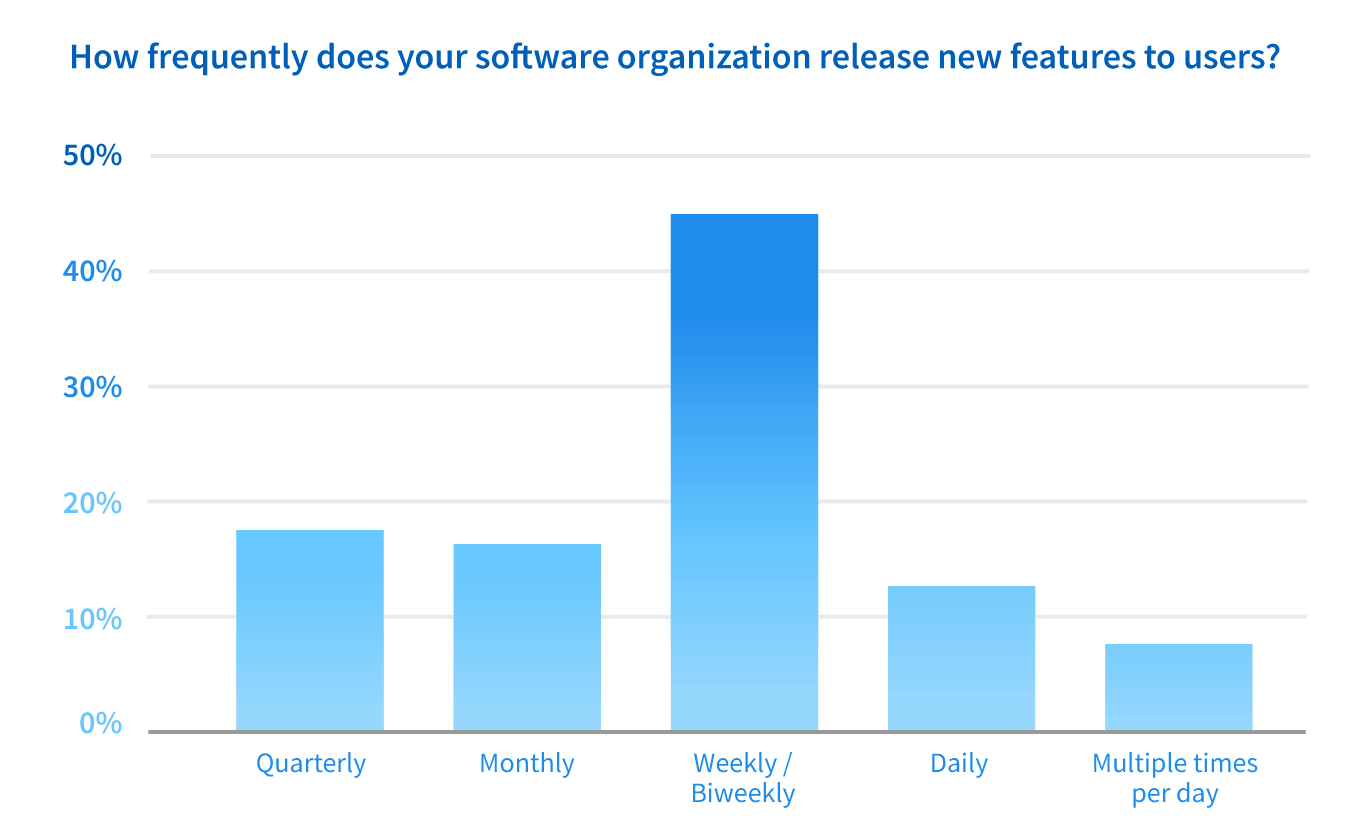
The latest DORA report from 2019 finds that 46% of organizations deploy code to production at least once per week. We went further to ask not just about deploying code, but about releasing it to users. We found the pace to be in line with DORA’s findings.
Of the organizations we spoke to, 67% release new features at least every 2 weeks. And 20% of all organizations are releasing at least once per day across one of their teams. While this may be spread across multiple teams, this is still a very impressive cadence!
Rapid releases too often break user experience
Another finding from the DORA 2019 survey was that 23% of software changes fail in organizations that deploy code weekly or less frequently. So we set about to understand this. Why is this happening? And what’s going wrong?
27% of the organizations we surveyed said they commonly experience downtime after releasing a feature. That could be the result of a breaking change or poor performance, often when a production environment behaves differently than staging. Looking more closely at the reasons for change failures, 82% of teams commonly experience bugs or defects after releasing features. And 23% of teams experience slow pages or database queries. In large scale Fortune 500 enterprises these issues can be extremely costly. IDC finds that an hour of downtime can cost upwards of $500K.
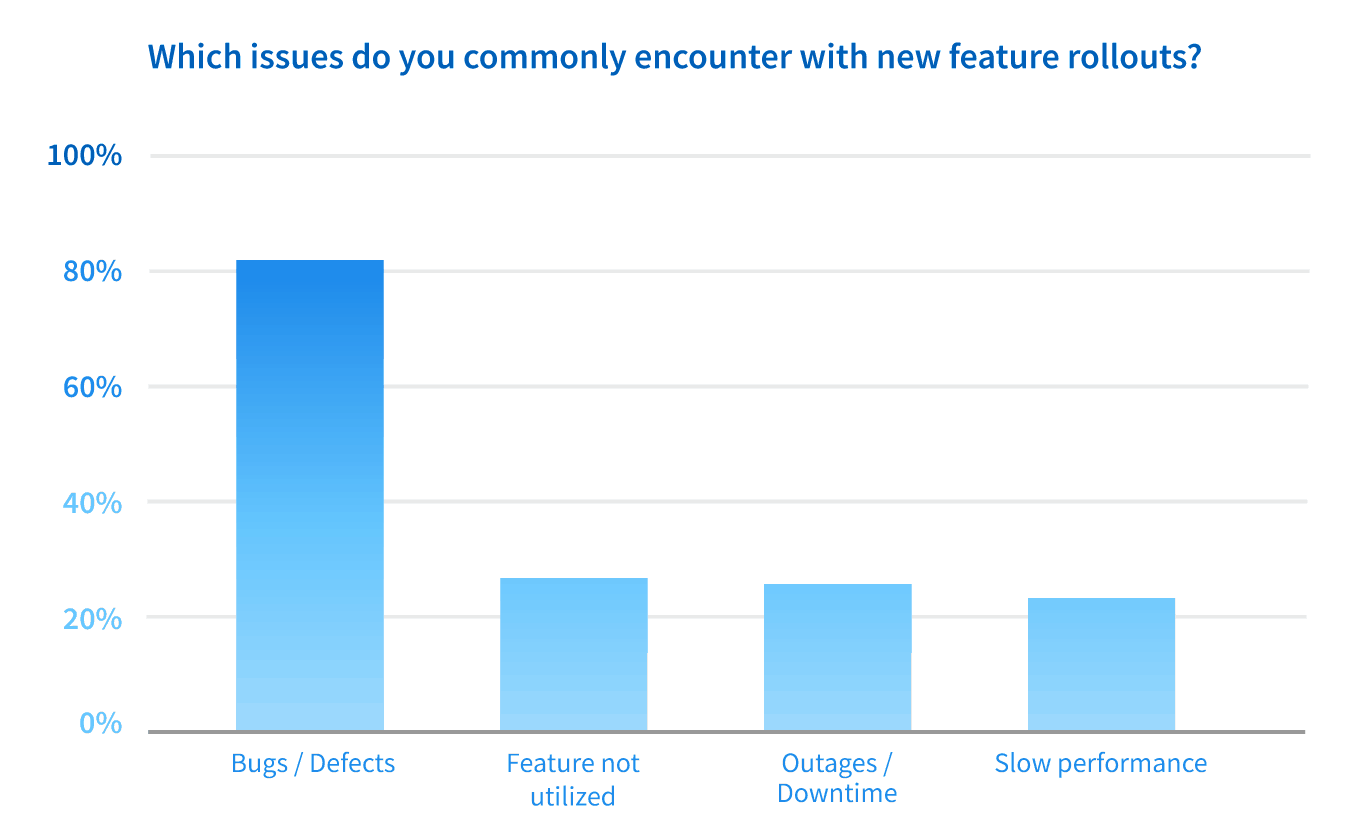
And speaking of costly, 27% of teams found that new features were often poorly adopted or utilized. That’s a lot of development and operational effort for something that didn’t work out!
Most of these issues require more time and rework
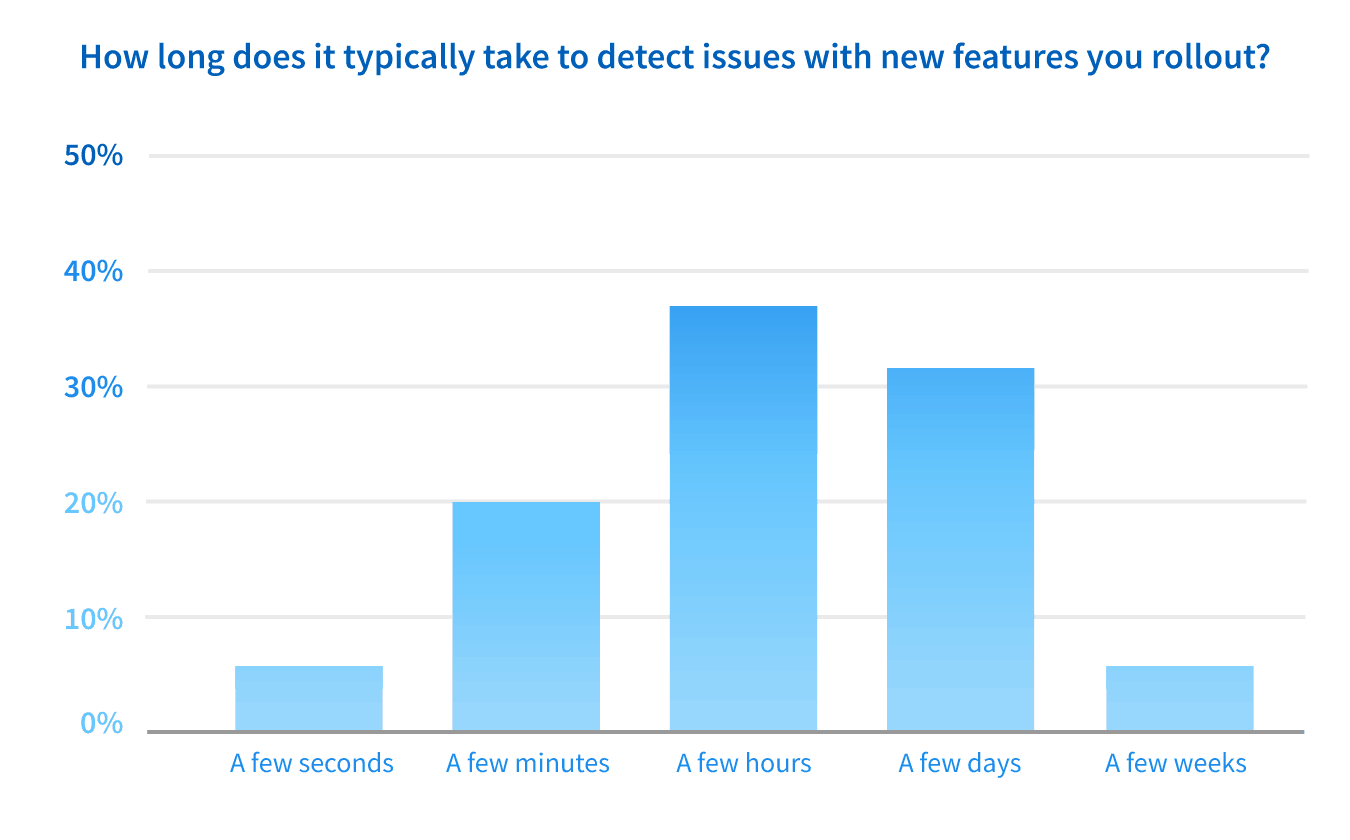
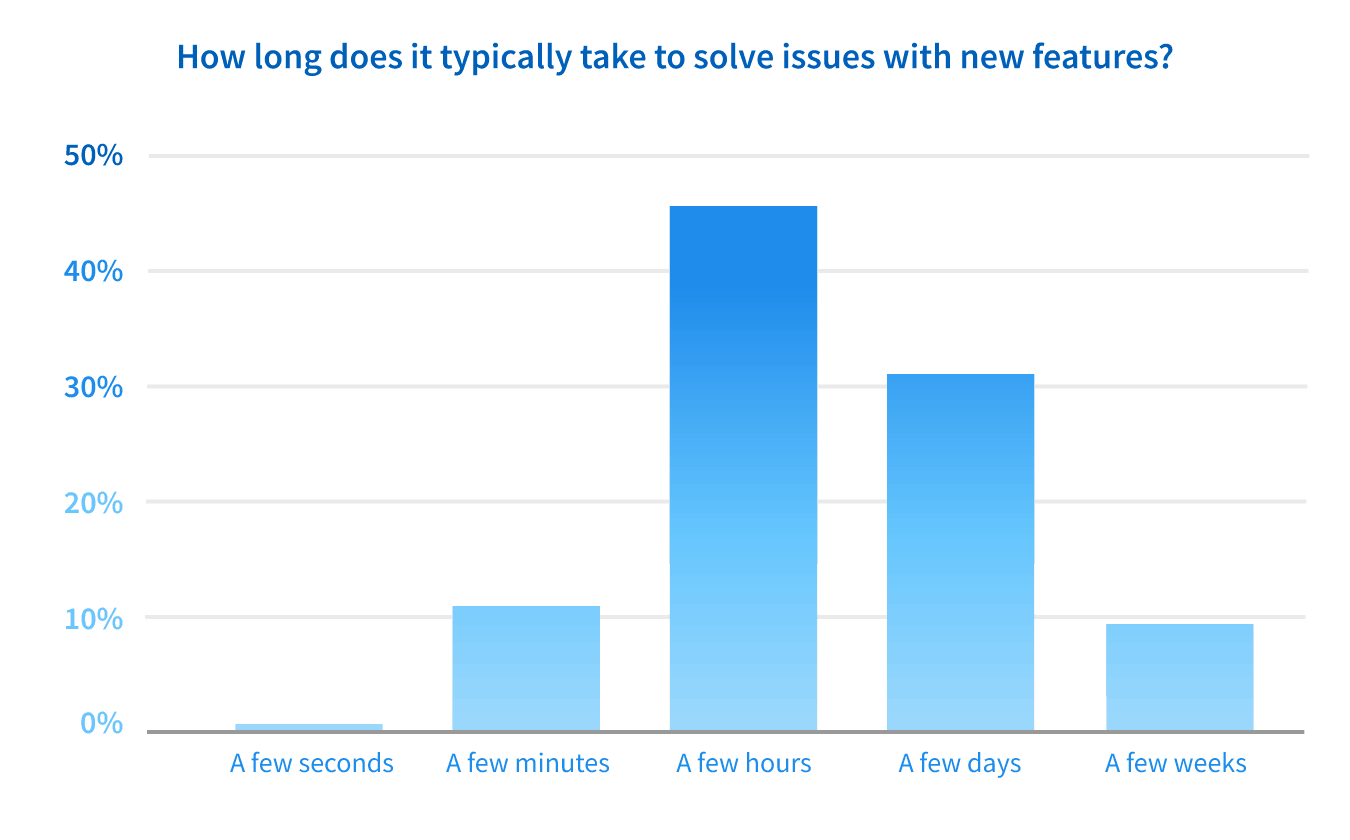
Not only do teams frequently have bugs, performance issues, and downtime during a feature release, all of this takes time to find and fix. This impacts two key metrics, mean time to detect (MTTD) and mean time to resolve (MTTR). 74% of teams take greater than 1 hour to detect issues with new features and 38% take more than 1 day.
Once an issue is found, teams also often have to roll back code or hotfix it in production. Both of these practices can introduce additional risk. Of our survey, 41% of teams rollback or hotfix more than 10% of new features. If we add the numbers of teams that reported they do both hotfixes and rollbacks to those who do one or the other, we see that 29% of teams hotfix more than 10% of new features and 26% frequently roll back new features.
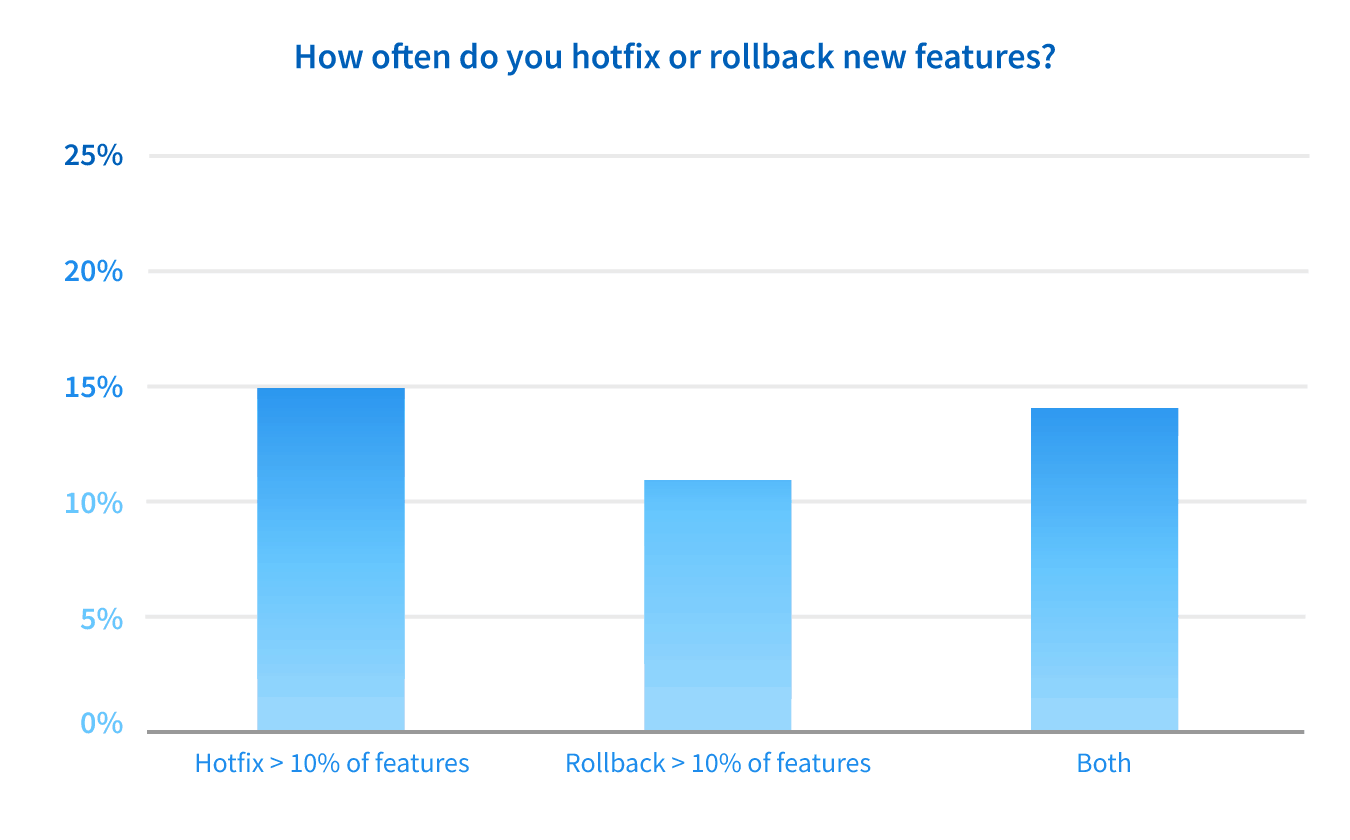
And hotfixes and rollbacks take even more time. The mean time to resolve (MTTR) for the teams we surveyed was greater than 1 day for 40% of teams and greater than 1 hour for 88% of teams.
The road ahead
Given that software development teams are already moving quickly, and in the process of deploying and releasing to production even more rapidly, how can we solve some of these issues? We’ve got a few tips:
- Catch bugs and performance issues before they create downtime. Practice gradual rollouts that expose new functionality to internal users, beta testers, and then progressively to large portions of your production users. This can help reduce the impact of an issue even when you weren’t able to catch it in staging. Feature flags can help you make gradual rollouts a reality.
- Tie together your application monitoring, error monitoring, and feature flags. Catch those bugs and performance issues as quickly as possible with integrated feature monitoring that can both detect small changes in performance or errors and can assign a root cause to the feature at fault. Leading organizations like Booking.com can do this in less than 3 minutes after a release.
- Avoid unnecessary work and redirect your team to features that have true impact. We found that 27% of organizations commonly released features that didn’t hit the mark. Finding these using experimentation to prove out effectiveness can ensure that all the sweat and tears you pour into your development process are valued in the end.
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.
Switch It On With Split
The Split Feature Data Platform™ gives you the confidence to move fast without breaking things. Set up feature flags and safely deploy to production, controlling who sees which features and when. Connect every flag to contextual data, so you can know if your features are making things better or worse and act without hesitation. Effortlessly conduct feature experiments like A/B tests without slowing down. Whether you’re looking to increase your releases, to decrease your MTTR, or to ignite your dev team without burning them out–Split is both a feature management platform and partnership to revolutionize the way the work gets done. Switch on a free account today, schedule a demo, or contact us for further questions.