
When you ask enough people how they do Continuous Delivery, you see some interesting themes emerge. I interviewed a variety of companies while researching CD in the Wild, and learned some surprising things. There’s more than one way to succeed with Continuous Delivery, but there are also some fundamental principles that everyone seems to eventually congregate towards. In this article I’ll summarize four of the common themes I saw across the various organizations I talked with that were succeeding with Continuous Delivery.
Focus on reducing batch size
Every high-performing continuous delivery team I spoke with placed an extremely high value on reducing batch size — reducing the number of changes involved in any given production deployment. In fact, some stated that their release process simply wouldn’t be sustainable if batch sizes grew too large. Many teams strived to get all the way to single-piece flow, with every source code commit from an engineer went to production as a separate deployment.
Reducing batch size is also associated with increasing deployment frequency — making lots of small deployments — and reducing lead time — the time it takes a change to move from an engineer’s keyboard into a user’s hands. The research described in the book Accelerate identifies a relationship between those measures (which they characterize as delivery performance) and overall organizational performance. Given that, it’s no surprise that organizations place value in reducing batch size — it drives broader organizational performance.
Your architecture dictates your release process
Some engineering teams are working on large monolithic systems, while others are working in an ecosystem of many small services. These architectural approaches have large consequences when it comes to ownership of deployable artifacts, and in turn on how you approach release management. A microservice architecture implies many small, independently deployable artifacts, each owned by a specific team. In contrast, with a monolithic architecture, multiple teams are often working on the same deployable system.
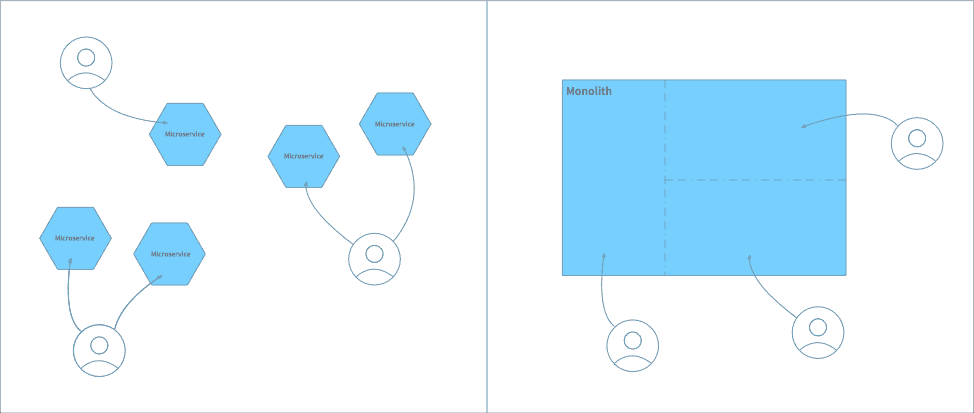
This ownership distinction — whether a deployable artifact is worked on by one team or multiple teams — has interesting implications when it comes to engineers moving a change into production. When preparing to make production deploy, an engineer needs to understand exactly what changes they’ll be pushing out. That’s much easier when all changes are being made by a single team. If, however, changes from other teams have been landing in the codebase at the same time, then understanding the impact of a production deployment becomes much harder.
What this leads to are two distinct approaches to release management. When working with microservices the release process can be very lightweight, and operate at a very high tempo. It’s quite typical for a change that lands on the main/trunk to be in production within an hour or so, with the deployment managed entirely by the engineer making the change. In contrast, release processes are much more formalized and structured when working with monolithic systems, which in turn leads to a slower deployment tempo. A common approach is for changes to be batched up into a “Release Bus”, with a bus heading out to production every day or so.
Note that both types of release process can still provide the benefits of Continuous Delivery. While smaller batch sizes and faster deployment tempos are preferred — as we discussed above — we all have to work within the constraints of our existing architecture. The organizations I spoke with that are succeeding with CD have learned to embrace these realities, and tailor their approach accordingly.
Invest in a delivery platform
The most successful organizations that I spoke with while researching CD in the Wild have made significant investments in a custom delivery platform. These internal systems provide capabilities such as:
- Deploying a specific version of a service into an environment
- Requesting a hold on production deployments
- Signing off on a version as being ready for production
- Tracking which version of each service is deployed into an environment
- Showing a history of previous deployments
- Reporting which new versions of a service are available for deployment
- Performing data management tasks in an environment (such as reseeding test data or importing scrubbed production data)
- Reporting overall service health in an environment
- Providing a Service Registry—a way to view metadata about the service in an environment, such as team ownership, service dependencies, and quick links to production dashboards
While every organization was using some sort of CI/CD product for basic build and test capabilities, they all also ended up building most of this platform as bespoke software. Often this started as a set of small command-line tools but evolved into a full-blown web-based product.
Most of these delivery capabilities are provided directly to product engineers, empowering them to do self-service release management. Having to coordinate with an external ops team or a release engineer in order to get a change into production would be considered a serious impediment by the high-performing CD teams I interviewed.
Trunk-based development is ideal, but not required
I mentioned above that many of the organizations I spoke with strived for single-piece flow, with every commit flowing into production as a distinct deployment. This ideal is only achievable by teams practicing Trunk-based Development. However, that doesn’t imply that Trunk-based Development is a requirement for practicing Continuous Delivery. In fact, many of the organizations I spoke with used some form of GitHub Flow, with short-lived feature branches and PR-based pre-merge code review. This methodology does have a significant impact on lead time for changes — a change might take a day or two to arrive in a user’s hands, rather than an hour or two. It’s also easy for teams to slip into bad habits, leaving feature branches un-integrated for multiple days, which violates the principles of Continuous Integration and erodes many of the benefits that a Continuous Delivery approach would otherwise provide.
NOTE: Interested in learning more about trunk-based development? Check out our video, Trunk Based Development: Overview and Implementation An Interview with Split SRE Craig Sebenik.
Summary: There’s more than one way to do CD
In summary, we’ve seen that the main benefit of Continuous Delivery practices is the ability to increase deployment frequency and reduce lead time for a production change, which in turn corresponds to increased organizational performance. A focus on small batch sizes is the key to achieving this benefit, and while architectural choices and engineering practices can impact the extent to which you can reduce batch size, Continuous Delivery can still be applied successfully. If you’re serious about reaping the benefits of CD, expect to invest in a custom delivery platform that will allow you to scale your release management process by pushing it down to individual product engineers.
You can read more about these ideas, as well as other concepts identified by my research, by downloading a full copy of the Continuous Delivery in the Wild report.
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.
Switch It On With Split
The Split Feature Data Platform™ gives you the confidence to move fast without breaking things. Set up feature flags and safely deploy to production, controlling who sees which features and when. Connect every flag to contextual data, so you can know if your features are making things better or worse and act without hesitation. Effortlessly conduct feature experiments like A/B tests without slowing down. Whether you’re looking to increase your releases, to decrease your MTTR, or to ignite your dev team without burning them out–Split is both a feature management platform and partnership to revolutionize the way the work gets done. Switch on a free account today, schedule a demo, or contact us for further questions.