
A data pipeline is typically used to extract, transform, and load data from the source platform to the destination system. This process usually involves aggregating data from multiple sources, transforming, validating, and eventually loading it into the target system. Every now and then, a data pipeline requires a redesign. This could be due to constantly evolving customer requirements, system performance metrics (including cost, time, etc.), and more.
Split’s existing data pipeline for AWS S3 Inbound Integration sends feature flag event data through S3 buckets. The S3 Inbound Spark job reads customers’ files from S3 buckets and updates Split’s Event table. Then, status report files are generated and populated in the same S3 buckets.
As the customer demand for existing S3 Inbound Integration increased, so did the cost of scaling S3 Inbound Spark Jobs. Split investigated methods to reduce costs and also researched ways to enhance customer experience by reporting additional status file information. Based on the investigation, Split designed a new pipeline using its feature flagging capabilities. Split’s feature flags helped to perform A/B testing functionality to validate cost and load feature tests in production. Thus enabling controlled production rollouts without impacting the customer experience.
Existing S3 Inbound Integration Pipeline
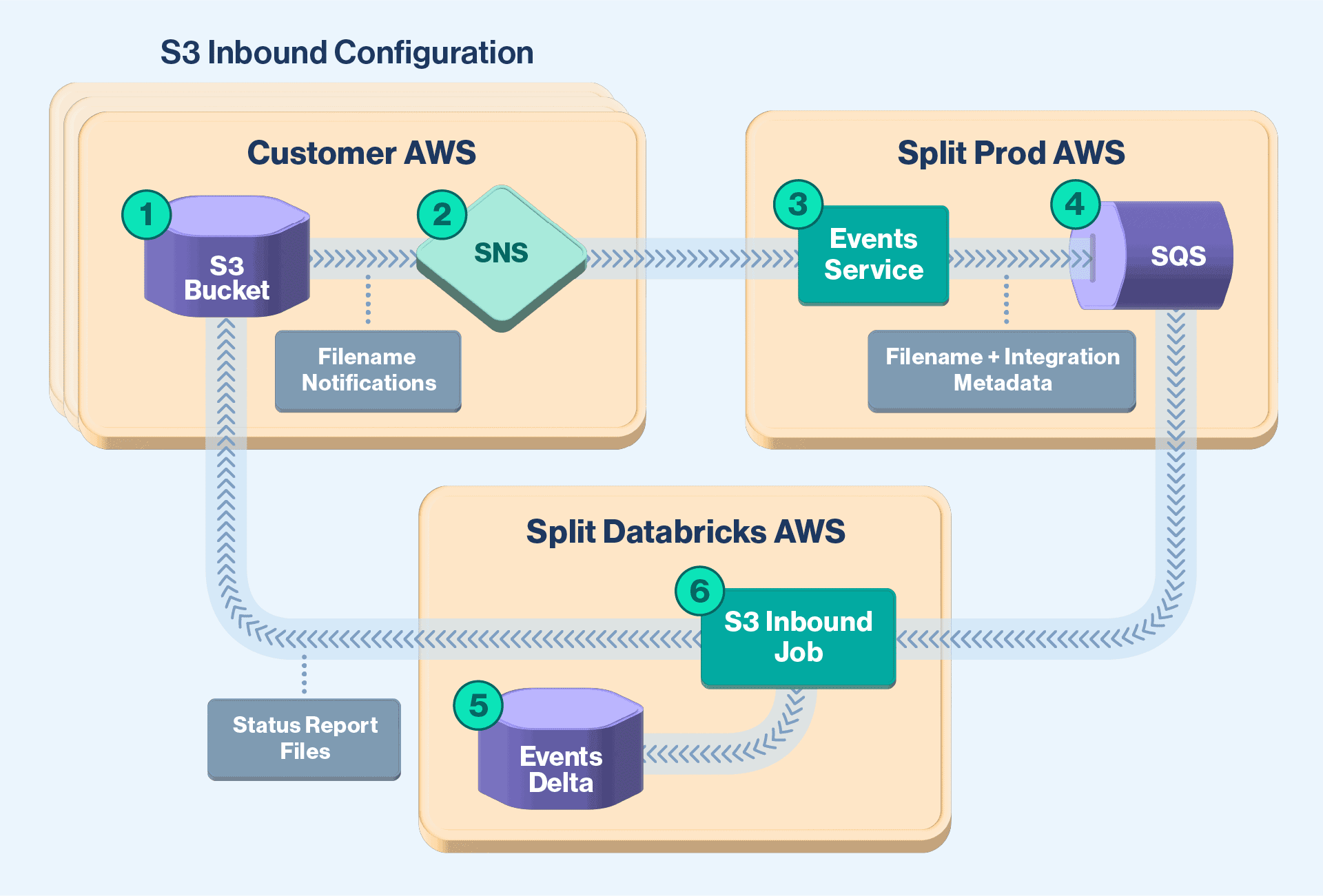
As depicted above, data in Split’s existing S3 Inbound Integration pipeline is ingested from the customer buckets, sending file notifications to an AWS SNS topic. Then, this SNS topic invokes Split’s Events service’s import endpoint to verify requests against existing integrations. As a result, Split asynchronously sends metadata of the file through the AWS SQS queue.
Split’s S3 Inbound Job runs on a cadence of every 10 seconds to determine if any new messages are present in the AWS SQS queue. Upon receipt of new messages, the S3 Inbound Job processes files to extract and store data within Split’s Events Table. Upon completion, S3 Inbound Job generates a consumed files status report and stores it in the configured customers’ S3 bucket.
Split’s existing S3 Inbound Integration pipeline was built using a single Spark Batch Job. As a result, all of the ingested data files to the existing pipeline were consumed sequentially. Needless to say, this causes bottlenecks for the S3 Inbound Integration. In order to increase throughput, we either vertically scale these instances or horizontally add more of them. The total cost of the existing S3 Inbound Job increases by more than 50% in terms of Databricks Units (DBU).
Additionally, the status report generated for the consumed files lacked valuable information that customers desired. For example, the total number of records in each file, error codes associated with them, and more.
New S3 Inbound Integration Pipeline
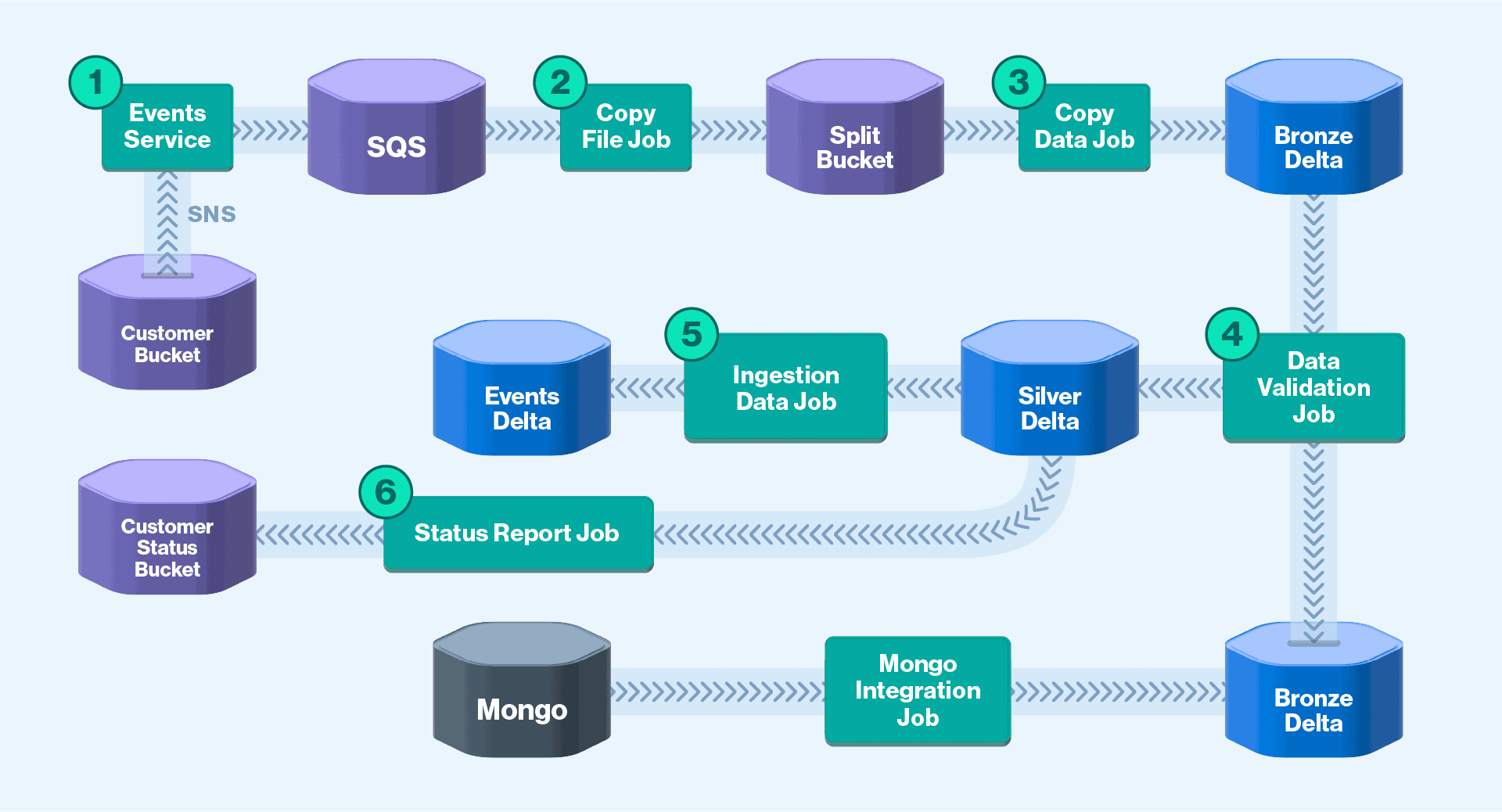
Similar to that of the existing pipeline, data is ingested in the new pipeline from the customers’ S3 buckets. This data then dispatches file notifications to an AWS SNS topic. Then, the Events Service verifies import requests against existing integrations and asynchronously sends file metadata through an AWS SQS queue.
However, now the new pipeline’s Events Service, as portrayed in Fig. 2, forwards messages to a new AWS SQS queue. A Copy File Job now reads these messages and places them into an internal Split S3 bucket. Next, a Copy Data Job uses Databricks’ Autoloader to efficiently load them into a Bronze table. Then, a Data Validation Job determines whether the data is valid or not against the MongoDB Integration Table.
Regardless of the validation result, this job places the validated data into the Silver Table. Afterward, a Data Ingestion Job performs data replication between the Silver Table and an Events Table. A Status Report Job reads the Silver Table to generate the Status Report into the customer’s S3 bucket.
Split’s new S3 Inbound Integration pipeline is designed with Spark streaming architecture. This new design change resulted in the parallel consumption of the ingested data files and reduced the resource utilization costs. The new pipeline’s responsibilities were split (pun intended) using the medallion architecture to separate out tasks. These tasks include ingestion, schema validation, data validation, and error feedback so customers can self-correct for further error handling.
Testing the Pipelines
Just building this new Inbound Integration pipeline was not enough. It was not only vital that Split reduce costs, but also ensure its scalability and reliability. For the latter, Split used feature flagging to run A/B testing between the existing and the new pipelines as seen in Fig. 3.
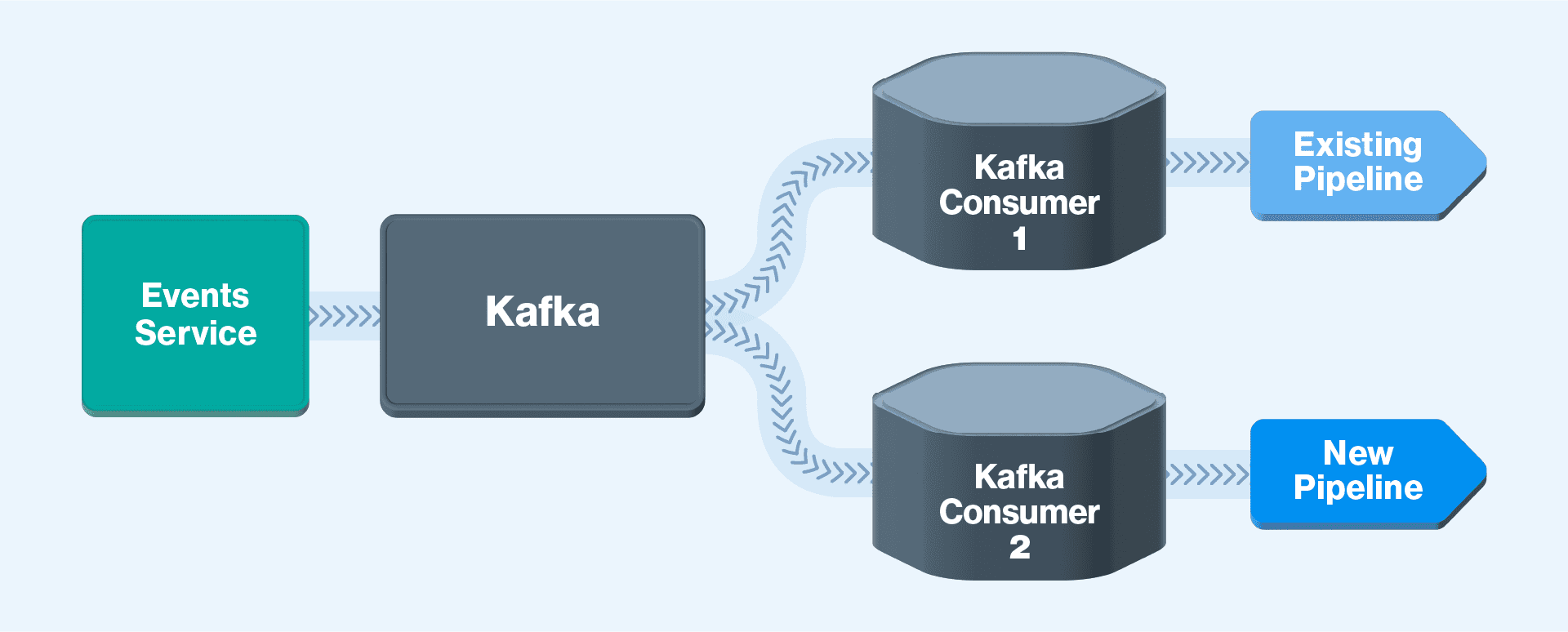
Typically, in a data pipeline, one would control data flow, say, through multiple Kafka consumer groups. As in Fig. 4, Kafka Consumer 1 dispatches data to the existing pipeline. Simultaneously, Kafka Consumer 2 pushes the same data to the new pipeline.
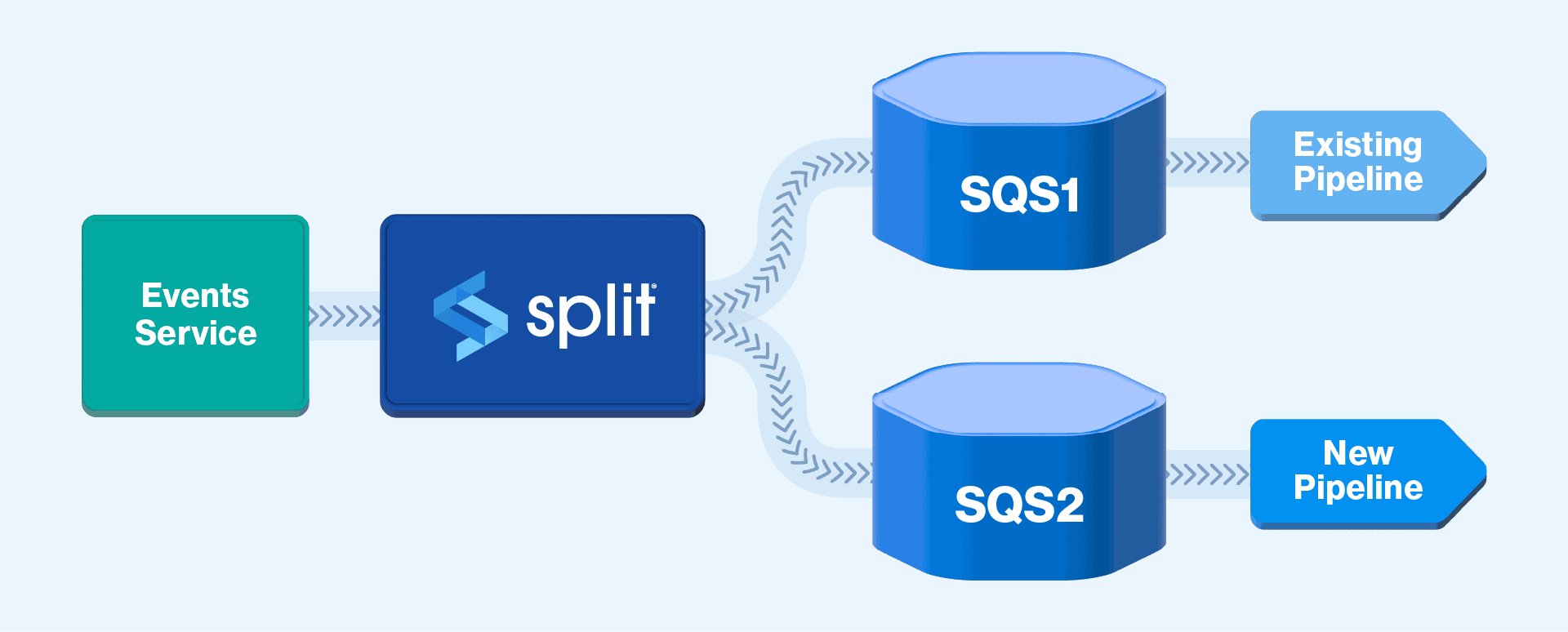
Split used a feature flag (Fig. 3) approach to control data flow into two AWS SQS queues. The first SQS queue sends data to the existing pipeline while the second sends it to the new pipeline. This allows both pipelines to seamlessly co-exist in the production environment for A/B testing.
Additionally, Split’s feature flag strategy allows to fine-tune the amount of data ingested through Split’s Allocate Traffic feature. It can also seamlessly onboard customers onto the new pipeline with Split’s Set Targeting Rules. Furthermore, Split’s Default Treatment assists in quicker rollbacks to the existing pipeline with a push of a single button. Whether it is on-demand or in the event of unforeseen production pipeline issues, Split has you covered.
Scalability and Cost Comparison
The new S3 Inbound Integration pipeline has six new Spark Jobs than that of the existing pipeline. These new jobs ensure that the new pipeline scales faster and better than the existing one. For example, picture a testing scenario where there are more than 50 GigaBytes of simulated data plus normal production data. This data can be ingested within 5-minute intervals, the new pipeline was able to process both data within 15 minutes. The pipeline is also horizontally auto-scaling into fewer instances. In comparison, the old pipeline would need 3 times as many instances and 10 hours to process the same data.
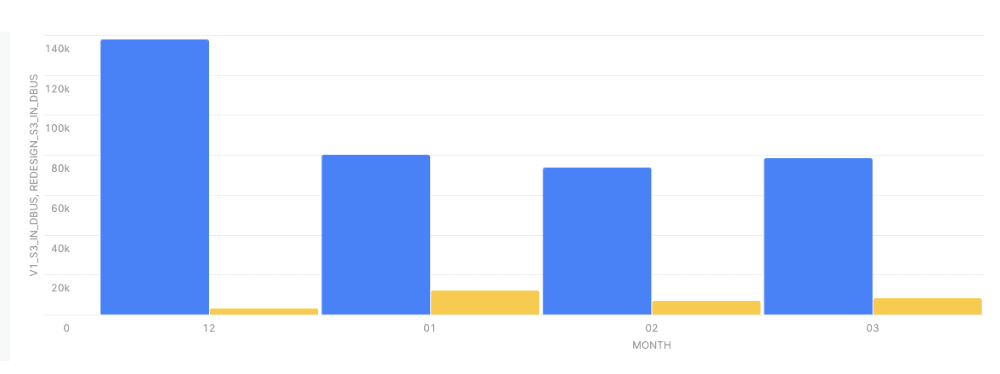
As for total cost measured in Databricks Units (DBU), the existing and the new S3 Inbound Integration pipeline significantly vary. This is depicted in Fig. 5, where the blue and yellow bars illustrate the total cost of the existing and the new pipelines, respectively. For any month, the S3 Inbound Integration pipeline’s resource consumption is at least 80% lower than that of the existing pipeline.
Summary
Split’s data pipeline for S3 Inbound Integration sends feature flag event data through AWS S3 buckets, generating status report files. The scaling costs of this pipeline are directly proportional to the increase in customer demands.
In conjunction with its feature flag strategy, Split designed its new S3 Inbound Integration pipeline to save on total operational costs. It can also enhance status file reports, perform scalability testing, and perform controlled rollouts in production environments. Additionally, Split’s feature flags allow for a faster and seamless rollback to existing pipelines, if needed. New S3 Inbound Integration pipeline scales better, requiring fewer and smaller instances, thereby saving 80% of the total operational cost.
With controlled rollouts, Split has successfully migrated a few customers to the new S3 Inbound Integration. It’s been active for more than one quarter in production environments with zero customer impact, providing enhanced status reports in near real-time.
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.
Switch It On With Split
The Split Feature Data Platform™ gives you the confidence to move fast without breaking things. Set up feature flags and safely deploy to production, controlling who sees which features and when. Connect every flag to contextual data, so you can know if your features are making things better or worse and act without hesitation. Effortlessly conduct feature experiments like A/B tests without slowing down. Whether you’re looking to increase your releases, to decrease your MTTR, or to ignite your dev team without burning them out–Split is both a feature management platform and partnership to revolutionize the way the work gets done. Switch on a free account today, schedule a demo, or contact us for further questions.