
Feature Parity Testing, sometimes referred to as TAP compare testing, ensures a new system behaves the same as an old one. It is used when replacing part or all of an old system with a new one. At a high level, you mirror your traffic to both systems and compare the results, logging any that are different. Unlike many other types of tests, it relies on actual traffic rather than test scenarios written by an engineer. This makes it a great way to identify forgotten features or find broken edge cases not caught in other forms of testing.
So how do we set up feature parity testing? First, you’ll need an identical interface on the old and new systems. You can create the interface on your new system that matches your existing one. Or add a thin façade on top of the old system that is the interface you want on the new one. Every scenario is different, but if you want to change your interface, I recommend adding the façade.
Now that your two systems have the same interface, it’s possible to add a feature flag that controls traffic to each system. This will seamlessly move the traffic between them.
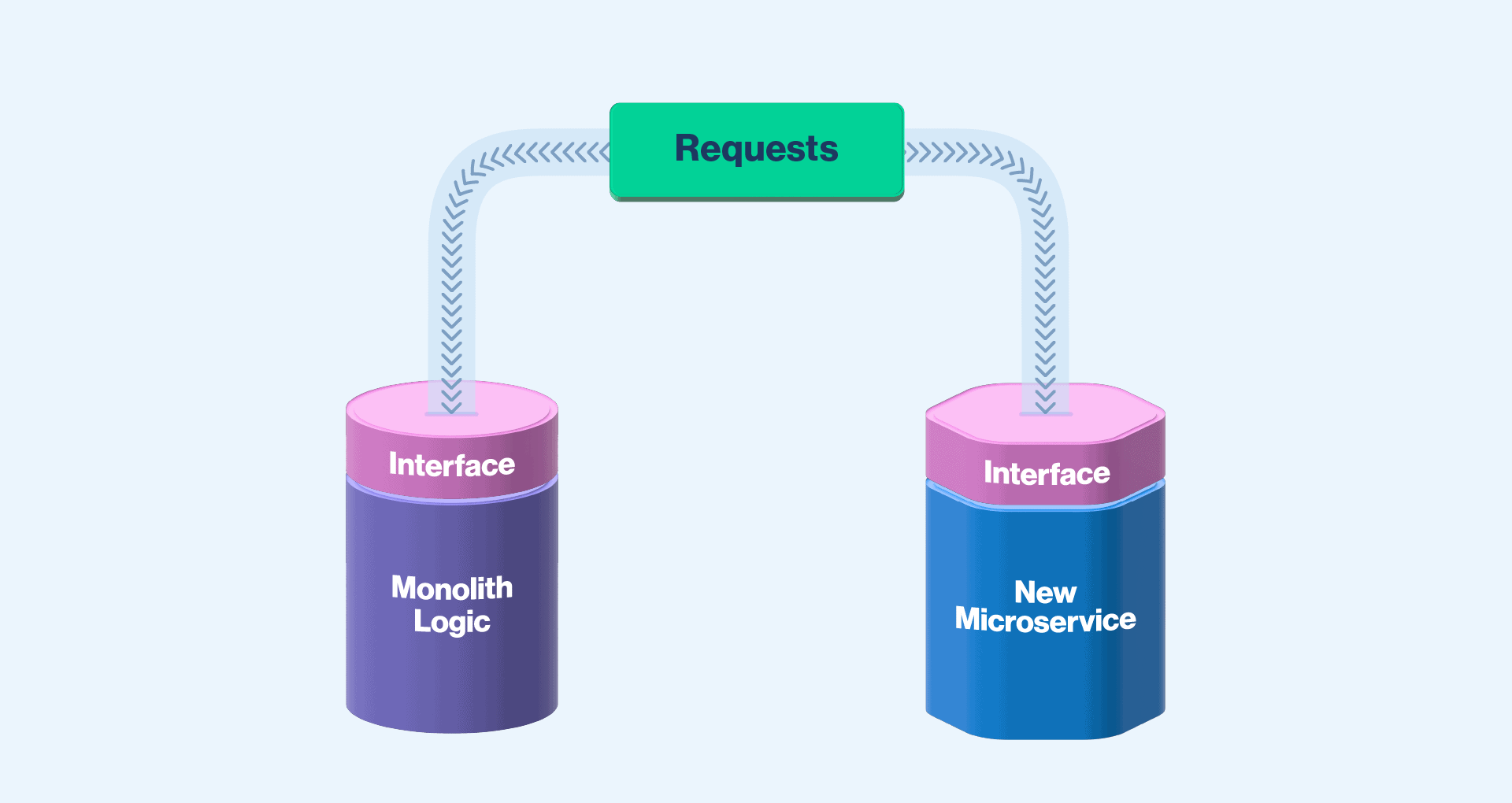
How to Add Feature Flags to Your System For Parity Testing
If you’re using a feature flagging product, such as Split, this allows you more than two treatments. As a result, you can set this up as four options: NEW, OLD, MIRROR, and PARITY. NEW routes all of the traffic to the new system. OLD sends all of the traffic only to the old system. MIRROR sends the traffic to the old system and also asynchronously sends it to the new system. PARITY does the same thing as MIRROR, but also sends the response from the old system to compare and log when the responses don’t match. If you’re using a product that only allows two treatments, you can do something similar but with more overlapping flags.
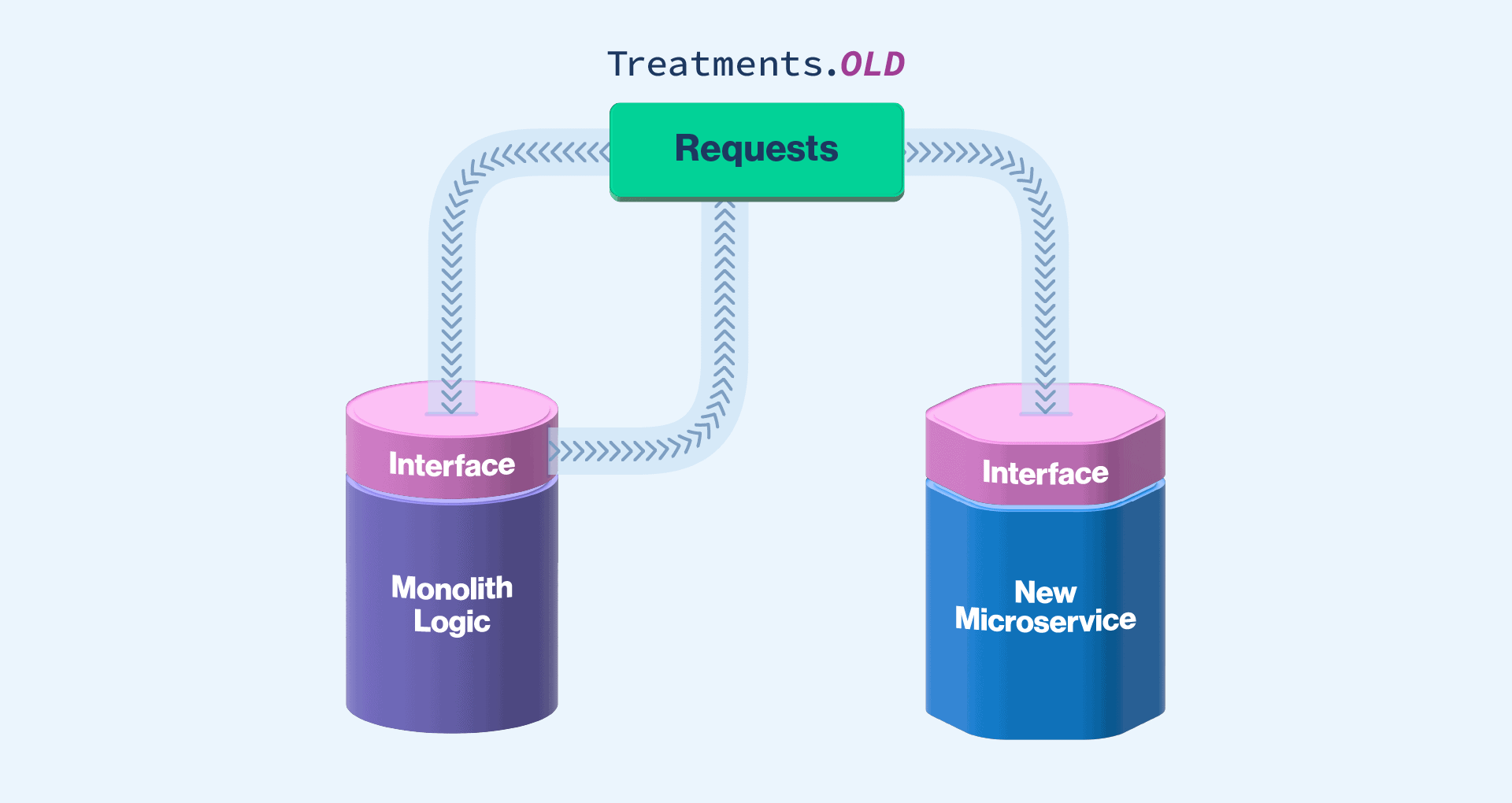
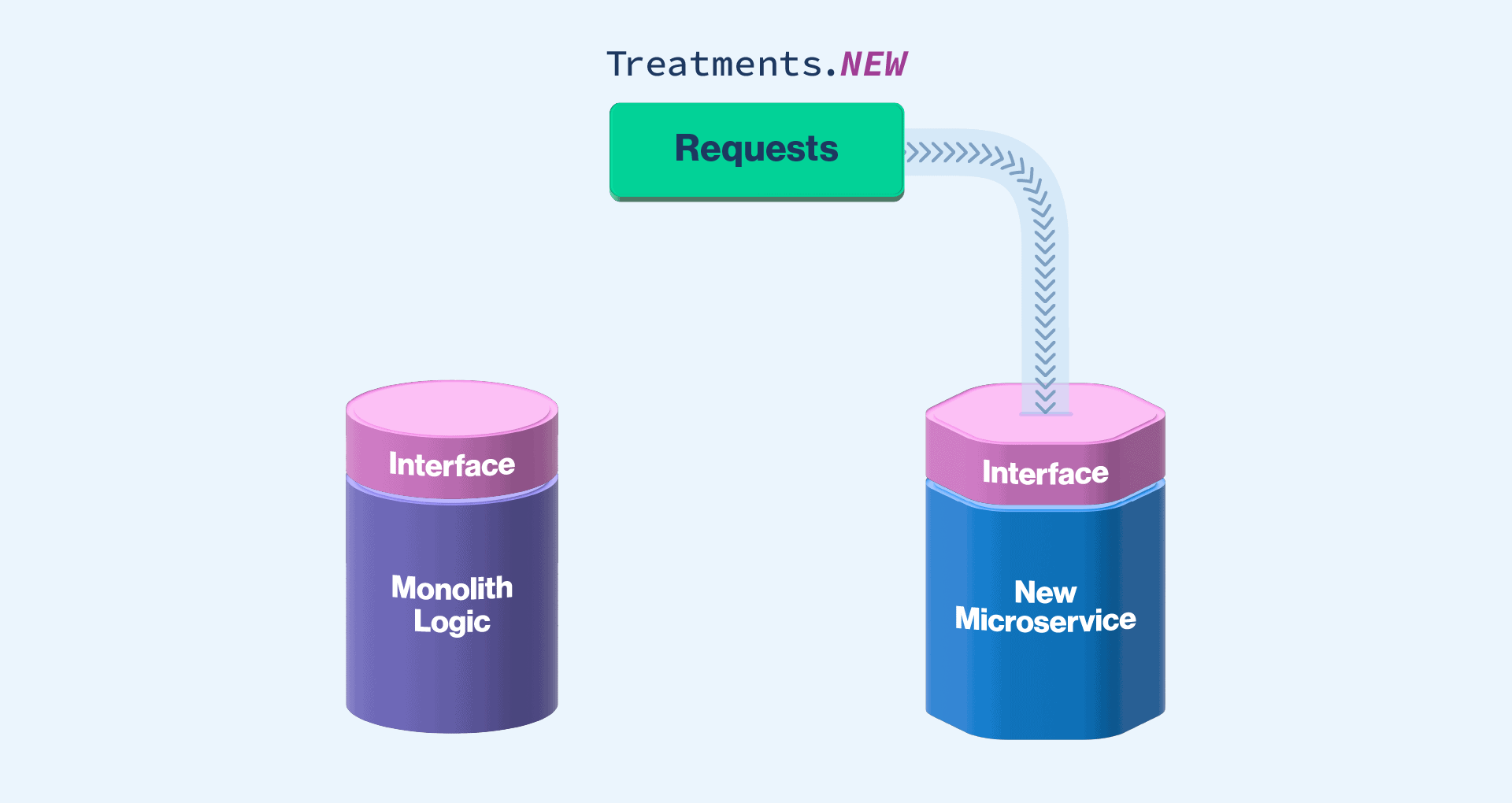
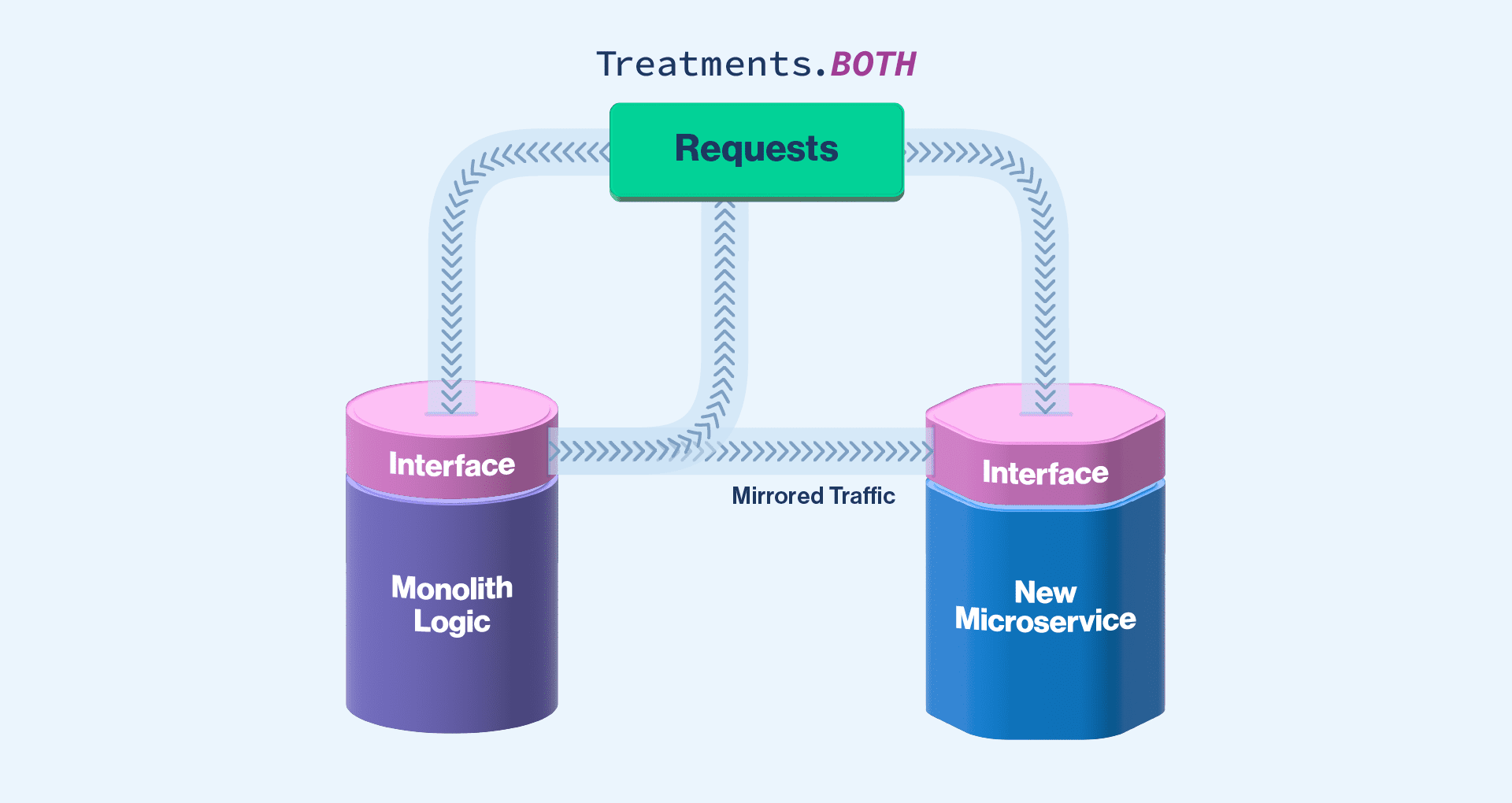
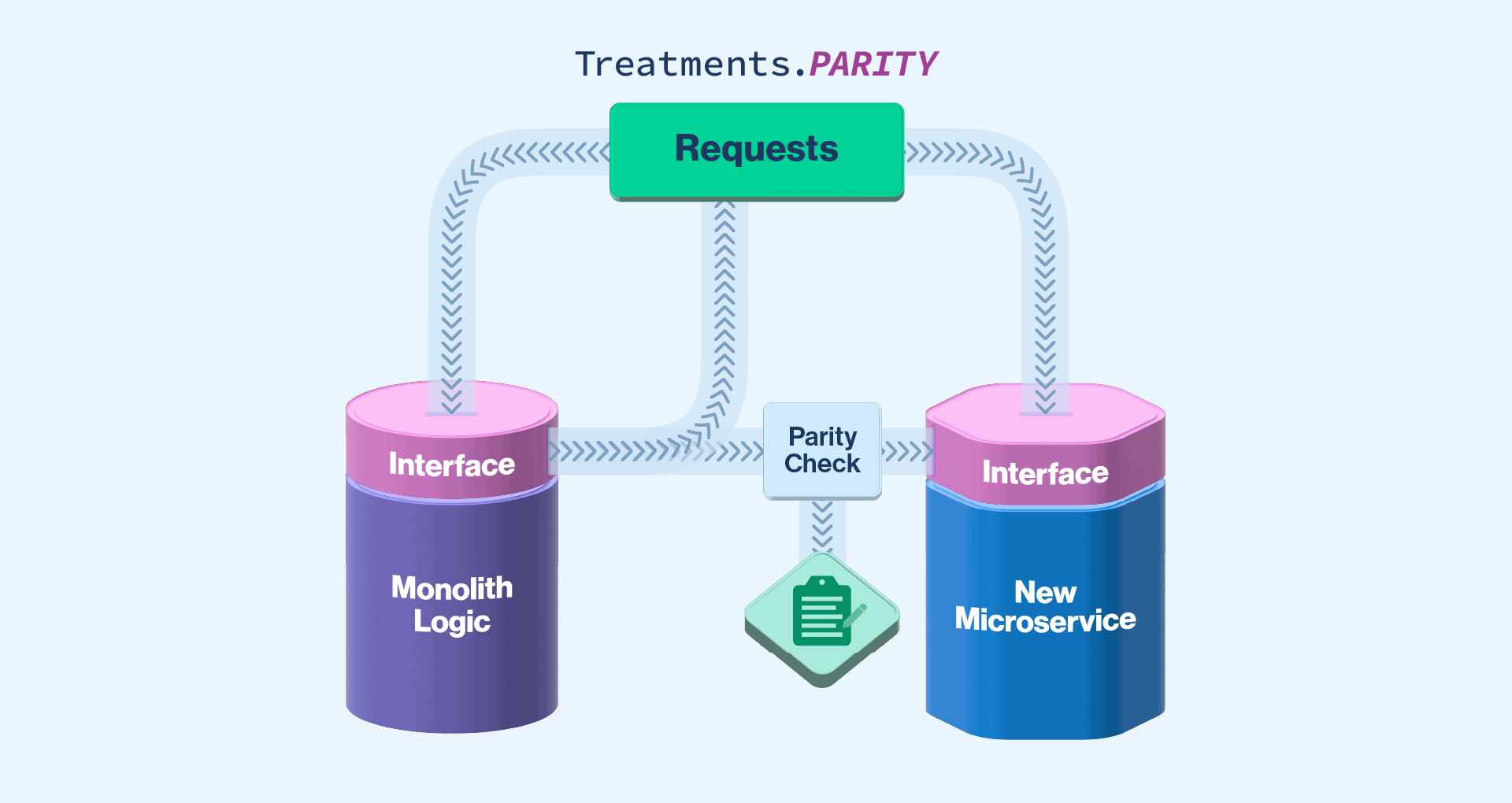
What might the code look like for this? I will use a scenario we had at Split. We replaced our existing authorization code with a new service, separating it from our monolith. In this case, we put in the four feature flag treatments mentioned above. Our code looked something like the following:
private void parityCheckInterface() {
String systemMode = _splitClient.getTreatment(orgId, Splits.SYSTEM_MIGRATION.splitName(), attributes);
if (Treatments.ON.equals(systemMode)) {
return callToNewSystem(params);
}
String oldResult = callToExistingSystem(params);
if (Treatments.OFF.equals(systemMode)) {
return oldResult;
}
CompletableFuture.runAsync(() - > {
String newResult = callToNewSystem;
if (Treatments.PARITY.equals(systemMode) && newResult != oldResult) {
this._statsSender.send("newsystem.parity.result", "parity:false");
logger.warn("eventName=SystemParityProblem params={} newResult={} expectedResult={}", new Object[] {
params,
newResult,
oldResult
});
}
});
return oldResult;
}As you can see, this does what we described above. If the treatment is ON, we only call the new system. If it’s OFF, we only call the old system. If it’s either MIRROR or PARITY, we send an asynchronous call to the new system after receiving the response from the old system. Then for PARITY, we compare the responses and log if they differ.
How to Roll Out Parity Testing
Now that we have the code set up, how did we roll it out? When we created the feature flag, we started with 100% of our traffic on OLD. OLD was also our default treatment. If something went wrong, our existing monolith already worked, so we wanted to default back to this. After deploying our new authorization service, we used a percentage rollout to slowly turn on some traffic to MIRROR. This allowed us to see if the infrastructure could handle the traffic.
At this point, we didn’t yet care about the correctness of the service. Once we were confident with the application logic on the new service and saw it successfully handling the traffic, we started rolling out PARITY. If we had found logs for mismatched responses, we could have switched the feature flag back to MIRROR. Then we can figure out what was going on (or off entirely if we didn’t think we’ll learn anything new from MIRROR).
It could have also been helpful to turn PARITY on for a single test account. This allows us to do exploratory testing and narrow down exactly where the error is coming from. Once PARITY was 100% on and no longer logging differences, we switched the feature flag to NEW. After we ran our new system and were confident that everything was working, we removed our old system and took out the feature flag.
Moving Between Two Data Stores
That first example involves moving to a new service. In this second example, we were switching data stores. In this case, we actually used two feature flags. The first flag was for writing and had two states, OLD and BOTH. The second flag was for reading and also had two treatments, OLD and PARITY. You might notice that there could easily be a third state on each, NEW. However, if we switch to a NEW state which only reads and writes to the new datastore, it will be nearly impossible to roll back. Therefore, we should remove the flags and clean up the code instead.
For the two data stores, we start with reading and writing from the old data store and the flags are accordingly set to OLD. Then, once the new data store is ready, we start writing to both but still reading from the old store. Next, we run a migration to move all the existing data to the new datastore while reading from the old and writing to both. Once the migration is complete, we should have all data in both places.
At this point, we’d want to turn on the parity mode for reading. This will compare the data read from the old datastore and the new datastore. This should allow us to catch if there was a problem with writing, migrating, or reading. If we find a problem, we can switch back to only reading from the old data store until the problem is fixed to avoid excess noise.
Parity testing can feel too hard to implement, but feature flags make it easy. Especially when dealing with legacy systems, it can be nearly impossible to understand everything the old system does. So having that extra layer of security is critical. And it can also be well worth the effort: at a previous company, we found that we had forgotten a massive feature in our migration but were able to catch that before it affected a single user. And that’s the power of parity testing.
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.
Switch It On With Split
Split gives product development teams the confidence to release features that matter faster. It’s the only feature management and experimentation solution that automatically attributes data-driven insight to every feature that’s released—all while enabling astoundingly easy deployment, profound risk reduction, and better visibility across teams. Split offers more than a platform: It offers partnership. By sticking with customers every step of the way, Split illuminates the path toward continuous improvement and timely innovation. Switch on a trial account, schedule a demo, or contact us for further questions.