
I’m part of Split’s frontend team, which manages a ~300K line source base. As you might imagine, we have many feature flags active in our source code at any given time. New flags are added regularly, and old ones are removed just as regularly.
Over the years, we have evolved how we add feature flags into our codebase. A lot of our focus has been on making it easy to add and remove these flags. Regardless of whether you’ve built your own in-house feature flagging system or use an enterprise-grade feature flagging platform like Split, the approach here can save you time and reduce the “cognitive load” of adding and removing flags.
Efficiency Doesn’t Always Mean Less Code
I often find myself thinking of the transition from assembly language programming to structured programming (functions, while loops, etc.). I’m sure people at the time argued that structured programming was inefficient. After all, expertly hand-crafted machine instructions could outperform the “cookie-cutter” code generated by a compiler. However, structured programming made it easier to think about and modify code. In the end, the machine instruction efficiency lost to the compiler was dramatically made up for by increased developer velocity.
We’ve made an analogous realization with feature flags, albeit at a higher level. Rather than “optimally” placing feature flag checks at individual lines of code, we wrap particular units (components, actions, reducers in our case) with things we call “togglers.” These togglers automatically pick the right unit to invoke based on the feature flag. The downside to this is that we end up with more code. But the upside is that our code is dramatically easier to reason about and modify.
How We Started Using Feature Flags
When we started off with adding feature flags to our codebase, we would add checks directly in the body of particular functions:
const MyComponent = (props) => {
const setting = flagSDK.getValue(MY_FLAG, userId);
if (setting === "on") {
// show new feature
} else {
// show old feature
}
};This is the straightforward way to add javascript feature flags and certainly the most efficient feature flag management strategy in terms of lines of code. This lets you hand-craft your use of feature toggles in the optimal location, minimizing code duplication.
However, this leads to two problems:
1. Removing These Flags Becomes Very Challenging
Often, at the end of a rollout, the person removing a flag is either not the person that put it in, or can no longer remember the fine details of the code. This inevitably makes the removal a cognitively challenging task.
This is even worse if multiple people have been modifying the code in the intervening time, and the code has suffered the inevitable “rotting” that results from different functionality jammed in on tight deadlines.
What seems like a simple “just remove the conditional” actually requires that you think through each logical flow (on both sides of a boolean flag or all sides of a multivariate flag), identify orphaned variables, functions, classes, files, and so on. This often makes the process significantly more laborious.
NOTE: Interested in learning more about how to scale institutional knowledge across multiple teams? Check out our fireside chat with Transposit CTO and co-founder Tina Huang and Split CTO Pato Echagüe.
2. Flags Increase the Effort To Reason About Code Modifications
When you modify code that has a feature flag in it, you need to be aware that the logic on each “side” of the feature flag can be substantially different. You must ask yourself something like: “So if I add this line here, how will it be affected by the multiple (sometimes quite different) flows that go through it?”
In theory, this is no different than any other branch in the code, but in practice, feature flags often carry a kind of logic change that isn’t “natural.” So once you are using feature flags in your functions, it can become surprisingly laborious to maintain multiple features.
Like everyone using feature flags seriously in software development, we wondered how we could make this easier.
Our initial step was to push the feature flags into our Redux store (which by itself is an interesting topic, but for another time). This let us start to decouple some of the “flagging” from the individual lines of code. If you are not familiar with dependency injection in the React/Redux world, this means that we started to pull some of the mechanics of checking a flag out of the individual functions in our components, and put it in a central store that then gets “injected” into individual components:
const MyComponent = (props) => {
const { myFeatureOn } = props;
if (myFeatureOn) {
return <div>NEW version!</div>;
} else {
return <div>Boring old version!</div>;
}
};You can see this isn’t a big step, but it did begin to “loosen up” our thinking about where the flags could be handled.
We Think About Javascript Feature Flags As Togglers
That loosening of our thinking allowed us to make the next important leap: If the heart of the flag was outside the body of code consuming it, why not pull the knowledge of the flag entirely out?
The natural place to start in a UI world is with a UI component since a UI component has a very clear boundary. Rather than the architecture being a body of code with a flag evaluation in it:
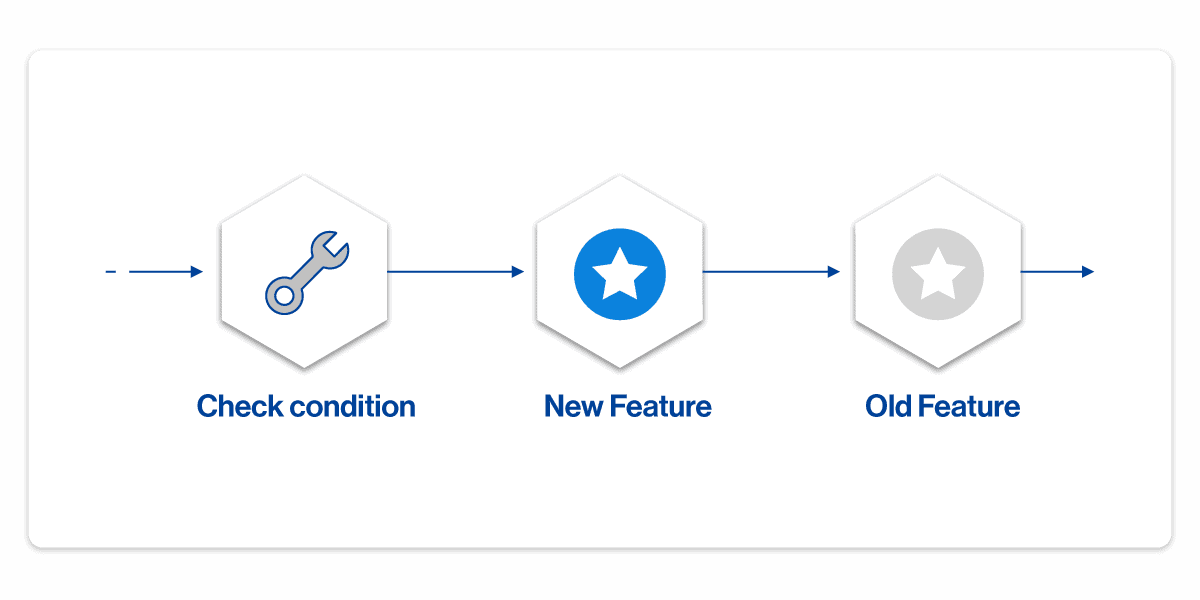
We switched the model to be a flag evaluation with two (or more) versions of the code:
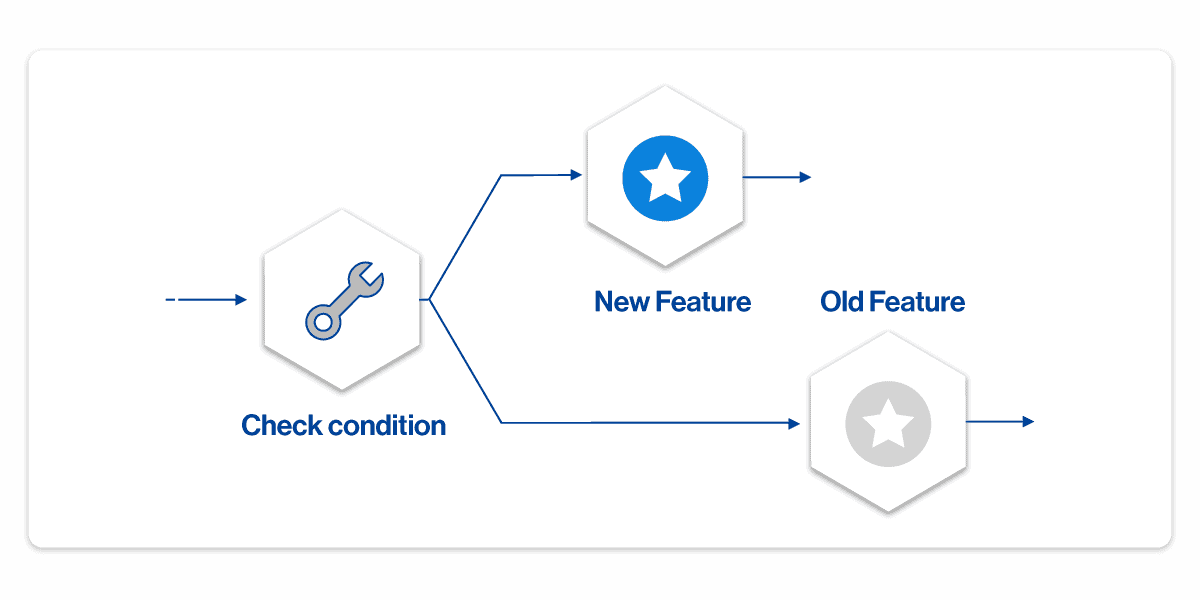
That is, we built a proxy that was only smart enough to know to evaluate a feature flag and then deliver flow of control to one of the variations.
What this looks like in terms of code is:
import { componentToggler } from "@split/utils";
import { MY_FEATURE } from "@split/constants/features";
import { MyComponent as Legacy } from "./Legacy";
import { MyComponent as MyFeatureOn } from "./MyFeatureOn";
const MyComponent = componentToggler(MY_FEATURE, MyFeatureOn, Legacy);
export { MyComponent };We called these proxies “togglers” because they simply toggle between multiple versions of the same component.
Here is an example of what it looks like to use one of these:
import { MyComponent } from "@split/components/MyComponent";
const SomeComponent = (props) => {
return <MyComponent>…</MyComponent>;
};You’ll note that you can’t tell the toggler is there!
Can This Pattern Benefit Your Feature Flag Implementation?
This pattern is not confined to UI components or generated HTML elements. For example, in a language like Java, you could use the aspect-oriented programming (AOP) pattern to build similar togglers outside of individual classes. In python, you could use decorators. You can likely think of an equivalent pattern that you could leverage in your chosen language.
Before you implement it for yourself, let’s talk about some of the pros and cons, based on what we’ve observed.
Pros of the Toggler Approach
By wrapping the core entities of the system with togglers we reap several benefits:
- Adding a feature flag becomes easy. We have a script that will take an existing component, make a second copy of it and set up the toggler function that wraps both.
- From there, it is easy to start modifying one component, acting as if the “legacy” version does not even exist.
- Reasoning about code is very easy. Because these are at “interface boundaries,” you do not have to contend with mixed logic in one routine. From the consumer’s point of view, there is no knowledge of the multiple in-app variations. From the consumee’s standpoint, there is likewise no knowledge of the variants of yourself that could be run. This means that when working on one of the component variations, you can focus your attention on that one feature.
- This also makes unit testing dramatically easier. Because the blocks of code being developed are completely distinct, it also means that the unit tests are completely distinct.
- Applying multiple feature flags is no harder than applying one (though the src subfolders and files can get more complex since you tend to end up with a file for each variation and togglers for each branch that you want to build).
- Removal of feature flags becomes nearly trivial. Since the knowledge of what is embodied on each “side” of the flag, is entirely encapsulated, removal of a feature flag is simply a filesystem transformation (delete the toggler and the old version, rename the new one to then be picked up)
- And removing the tests for the “legacy” version is just as easy:
rm Legacy.test.js.
Cons of the Toggler Approach
This approach does come with some tradeoffs, mostly in very specific situations:
- The most notable con is that it increases the amount of code in your codebase vs. simply adding flags on a line-by-line basis. As mentioned above, however, this is often not significant.
- This approach is optimal for the case where feature flags are being used to incrementally add new features. That is, where the expectation is that the newer version is soon going to become the only one. In this scenario, when bug fixes happen, they generally happen on just the newer side of the split. If your organization is focused on the highest-speed, most secure release process, you will mainly be incrementally adding new code in this way.
- In some cases, though, feature flags are used for parallel versions of features where there may be no plan to remove one of them soon. In this scenario, this approach to flags is not as desirable since when bug fixes need to be made, you will need to apply those fixes on both sides of the feature flag. At that point the code duplication can become onerous.
This Feature Flag Implementation Pattern Can Work For You Too
What we’ve talked about here is the idea of moving the application of your feature flags to the boundaries of logical units of code (components, classes, actions, etc) rather than at individual lines of code. The benefits of this are that it makes it significantly easier to reason about your code, easier to add and (importantly) remove the feature flags.
While a primary reason for using feature flags is to be able to measure the adoption of new features so that your company can make better business decisions, another purpose is to improve development velocity while reducing release risk. It is almost a truism that reduced conceptual complexity of your code is going to improve development velocity (less time thinking about adding logic, less time testing it, less time reviewing it), and improving the mechanics of adding and removing flags is also going to improve velocity.
All of the benefits are why we have adopted this pattern so extensively in our codebase, and why you should consider adopting a pattern like this in your own source code. Let us know what your own experience with this is!
Learn More About Implementing Feature Flags at Scale
Optimizing the introduction of feature flags into your codebase is, of course, just the tip of the iceberg in terms of the benefits that feature flags can unleash for your organization. You can protect your CI/CD pipelines and release processes, measure feature use in production environments, perform targeting and segmentation, run a/b testing without redeployment, and gather metric results and runtime insights to tailor your business decisions. These are just some of the additional benefits that can be built on the foundation of feature flags.
You can evaluate Split feature flags by using one of our SDKs, as documented in our help docs, or by using the Split API. Split SDKs can run client-side or on your server-side backend. The Split SDK repositories are open-source and viewable in GitHub.
Check out these resources from our team to learn more about how to confidently release features as fast as your team can develop them:
- How to Reduce Code Cycle Time with Feature Flags
- Feature Monitoring in 15 Minutes
- Feature Flagging with Less Mess
And always, make sure you catch all our new releases as they come out! Follow us on Twitter @splitsoftware, and subscribe to our YouTube channel.
Switch It On With Split
The Split Feature Data Platform™ gives you the confidence to move fast without breaking things. Set up feature flags and safely deploy to production, controlling who sees which features and when. Connect every flag to contextual data, so you can know if your features are making things better or worse and act without hesitation. Effortlessly conduct feature experiments like A/B tests without slowing down. Whether you’re looking to increase your releases, to decrease your MTTR, or to ignite your dev team without burning them out–Split is both a feature management platform and partnership to revolutionize the way the work gets done. Schedule a demo to learn more.
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.