
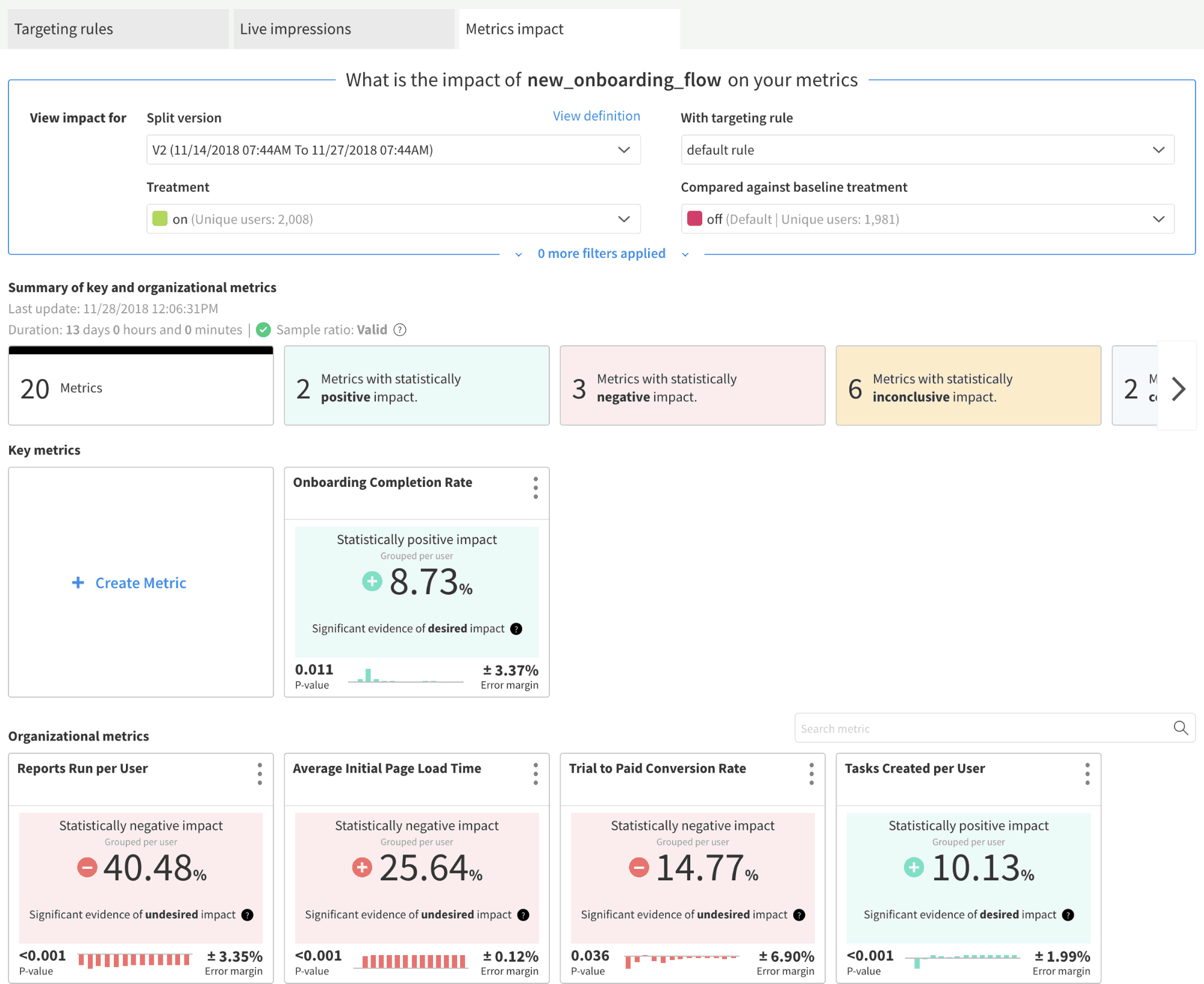
Split’s Metrics Impact page allows you to make powerful product decisions and positively influence your business goals. At Split, we are always improving how we can help our customers make these decisions more efficiently across the full application stack. In this blog, I will discuss best practices to achieve statistically significant results in your experiments and how Split can help you accomplish this.
Dynamic minimum detectable effect
With its new and improved calculations for statistical significance, the Split platform can accommodate an array of different customers and the metrics that are important to each. Previously the minimum detectable effect was fixed to 0.1 standard deviations. This setting limited some customers’ ability to achieve statistically significant results. Understanding the minimum detectable effect is imperative for significance testing. Also referred to as MDE, the minimum detectable effect captures the minimum change in your metric required to produce a statistically significant result with a given sample size. Whether you are experiencing large sample sizes and small effects or vice versa you can get to statistically significant results within Split.
Split’s dynamic minimum detectable effect is adjusted for each metric card based on the observed effect size and sample size since the start of the experiment. Put another way, Split’s decision engine will now inform customers of the number of samples (or time remaining) for the observed effect to become statistically significant. We believe this adjustment to how we utilize minimum detectable effect will assist our customers as they look to run experiments and understand how long these experiments must run for the observed effect to be statistically conclusive.
Helping you conclude experiment results with review periods
Experimental review periods is a common practice across sophisticated growth and experimentation teams. In some experimentation teams, there are no decisions made before the experiment has run for a set number of days. For example, a travel site might observe a spike in traffic on a Monday when people are trying to shake the Monday blues by exploring vacation options. If you only run your experiment for this 1 day it would cause an unfair representation of your entire customer base. Another example would be an online restaurant-reservation service where users may make a restaurant reservation for up to 4 weeks in advance. In this scenario, it would be best practice to make your review period 28 days to account for the full usage cycle— from making the reservation to walking into the restaurant.
In other words, the experimental review period represents a duration long enough for all of your typical customer types to visit the product and complete the activities relevant to your metrics. For instance, you may have different activity pattern at night versus during the day (set a one day period), or have a 30-day sales cycle (set a four week period). A commonly used value for experimental review period is at least 14 days to account for the weekend and weekly behavior of customers. We have built Split for any size team or organization, which is why we allow you to adjust the experimental review period to what is optimal for your business and customer patterns.
Making conclusions about the impact of your metrics during set experimental review periods will eliminate the chance of errors and allow you to account for seasonality in your data. We will always show your current metrics impact, but we will notify you if you are between review periods. We encourage you to only make conclusive product decisions during review periods.
Best practices to achieve statistically significant results
Experimentation can become difficult when you are faced with metrics that need a very long time to gain enough data for statistically significant results. In this case, it does not mean you cannot experiment. Instead, you can take actions to still achieve statistically significant results. If you have data limitations, begin your experimentation journey with more impactful experiments where a higher effect size is more likely. For example, it would be more beneficial to experiment with an entire redesign of your homepage versus a small tweak on a nested page. This will likely result in a higher effect size.
Choosing the right metrics for your experiment is an important part of your experiment design. A major factor of this decision is the sensitivity of your metrics. For example, if a user only purchases something from your product typically once a year, this is unlikely to be influenced by an experiment and therefore not cause a sizable effect size to statistically significant results.
Split also has product settings to help you increase your chance of reaching statistical significance.
Metric definition
Can your metric be redefined to be more sensitive? When creating the definition of your metric, you can apply a ‘Has done…’ filter, which means you are limiting the number of users that fit the criteria of that metric. This, in turn, will increase the sensitivity of that metric by removing unnecessary noise from your data.
Metric capping
Metric capping will allow you to cap the metric value for a particular customer during a set period of time. By capping the value, you minimize the effect of the bots or outliers in the data.
Event Triggering
Event triggering is a way to limit the sample size of your split to only users that are exposed to your treatment, this will remove the noise from your data and will help you reach statistical significance more quickly.
If you’re new to Split, get started for free to learn more about how you can make better product decisions with feature experimentation.
Get Split Certified
Split Arcade includes product explainer videos, clickable product tutorials, manipulatable code examples, and interactive challenges.
Switch It On With Split
The Split Feature Data Platform™ gives you the confidence to move fast without breaking things. Set up feature flags and safely deploy to production, controlling who sees which features and when. Connect every flag to contextual data, so you can know if your features are making things better or worse and act without hesitation. Effortlessly conduct feature experiments like A/B tests without slowing down. Whether you’re looking to increase your releases, to decrease your MTTR, or to ignite your dev team without burning them out–Split is both a feature management platform and partnership to revolutionize the way the work gets done. Switch on a free account today, schedule a demo, or contact us for further questions.